Further NLU and Dialogue State Tracking
Hugging Face’s Transformer
Attention 以及 Self-Attention
- 1、Attention
是神经网络中的一种机制,模型可以通过选择性地关注给定的数据集来学习做出预测。Attention的个数是通过学习权重来量化的,输出通常是一个加权平均值。
- 2、Self-Attention
是一种注意力机制,模型利用对同一样本观测到的其他部分来对数据样本的剩下部分进行预测。从概念上讲,它感觉非常类似于non-local的方式。还要注意的是,Self-attention是置换不变的;换句话说,它是对集合的一种操作。
而关于attention和self-attention存在非常多的形式,最常见的Transformer是依赖于scaled-dot-product的形式,也就是:给定query矩阵Q, key矩阵K以及value矩阵V,那么我们的输出就是值向量的加权和,其中,分配给每个值槽的权重由Query与相应Key的点积确定。
对于一个query以及一个key向量,$q_i,k_j \in R^d$,我们计算下面的值:
其中,$S_i$是keys的集合。
- Multi-Head Self-Attention
multi-head self-attention是Transformer的核心组成部分,和简单的attention不同之处在于,Multi-head机制将输入拆分为许多小的chunks,然后并行计算每个子空间的scaled dot product,最后我们将所有的attention输出进行拼接,
其中,$[.;.]$是concate操作,$W^q_i, W_i^k \in R^{dd_k/h}, W_i^v \in R^{d d_v/h}$是权重矩阵,它将我们的输出embeddings(Ld)的映射到query,key,value矩阵,而且$W^o \in R^{d_v d}$是输出的线性转化,这些权重都是在训练的时候进行训练的。
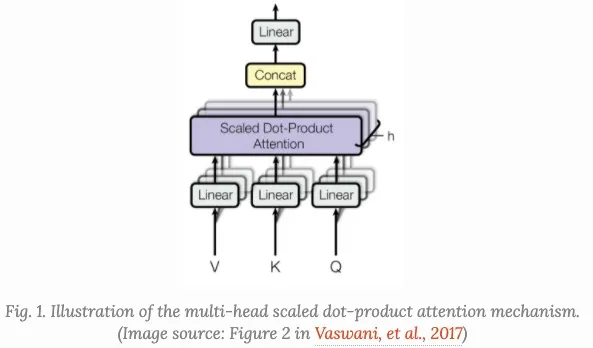
Transformer,很多时候我们也称之为”vanilla Transformer”, 它有一个encoder-decoder的结构,decoder的Transformer可以在语言建模的时候获得非常好的效果。
Encoder-Decoder结构
Encoder生成一个基于attention的表示,能够从一个大的上下文中定位一个特定的信息片段。它由6个身份识别模块组成,每个模块包含两个子模块、一个multi-head self-attention和一个point-wise全连接前馈网络。
按point-wise来说,这意味着它对序列中的每个元素应用相同的线性变换(具有相同的权重)。这也可以看作是滤波器大小为1的卷积层。每个子模块都有一个剩余连接和layer normalization。所有子模块输出相同维度的数据。
Transformer的decoder功能是从encoder的表示中抽取信息。该结构与encoder非常相似,只是decoder包含两个多头注意子模块,而不是在每个相同的重复模块中包含一个。第一个多头注意子模块被屏蔽,以防止位置穿越。
![]()
Improved Attention Span
提高Attention Span的目的是使可用于self-attention的上下文更长、更有效、更灵活。
1. Longer Attention Span(Transformer-XL)
vanilla Transformer有一个固定的和有限的注意广度。在每个更新步骤中,该模型只能处理同一段中的其他元素,并且没有任何信息可以在分离的固定长度段之间流动。也就是说层数固定不够灵活,同时对于算力需求非常大,导致其并不适合处理超长序列。
这种context segmentation会导致几个问题:
- 模型不能捕获非常长期的依赖关系;
- 在没有上下文或上下文很薄的情况下,很难预测每个片段中的前几个tokens。
- 评估是昂贵的。每当segment右移一位时,新的segment就会从头开始重新处理,尽管有很多重叠的tokens。
Transformer-XL解决来上下文的segmentation问题:
- 对于segments之间的隐藏状态进行重复使用;
- 使用位置编码使其适用于重新使用的states;
2. Relative Positional Encoding
为了处理这种新的attention span的形式,Transformer-XL提出了一种新的位置编码。如果使用相同的方法对绝对位置进行编码,则前一段和当前段将分配相同的编码,这是不需要的。
为了保持位置信息流在各段之间的一致性,Transformer XL对相对位置进行编码,因为它足以知道位置的offset,从而做出更好的预测,即$:i-j$,在一个key向量$k{T,j}$以及它的query之间$q{T,i}$。
3. Adaptive Attention Span
Transformer的一个关键优势是能够捕获长期依赖关系。根据上下文的不同,模型可能更愿意在某个时候比其他人更进一步地注意;或者一个attention head可能有不同于另一个attention head的注意模式。如果attention span能够灵活地调整其长度,并且只在需要时再往回看,这将有助于减少计算和内存开销,从而在模型中支持更长的最大上下文大小(这就是Adaptive Attention Span的动机)。
后来Sukhbaatar等人提出了一种self-attention机制以寻找最优的attention span,他们假设不同的attention heads可以在相同的上下文窗口中赋予不同的分数,因此最优的span可以被每个头分开训练。
4. Localized Attention Span (Image Transformer)
Transformer最初用于语言建模。文本序列是一维的,具有明确的时间顺序,因此attention span随着上下文大小的增加而线性增长。
然而,如果我们想在图像上使用Transformer,我们还不清楚如何定义上下文的范围或顺序。Image Transformer采用了一种图像生成公式,类似于Transformer框架内的序列建模。此外,图像Transformer将self-attention span限制在局部邻域内,因此模型可以放大以并行处理更多的图像,并保持可能性损失可控。
encoder-decoder架构保留用于image-conditioned生成:
- encoder生成源图像的上下文化的每像素信道表示;
- decoder自回归地生成输出图像,每个时间步每像素一个通道。
让我们将要生成的当前像素的表示标记为查询$q$。其表示将用于计算$q$的其他位置是关键向量$k_1, k_2……$它们一起形成一个内存矩阵$M$。$M$的范围定义了像素查询$q$的上下文窗口。
Image Transformer引入了两种类型的localized $M$,如下所示。
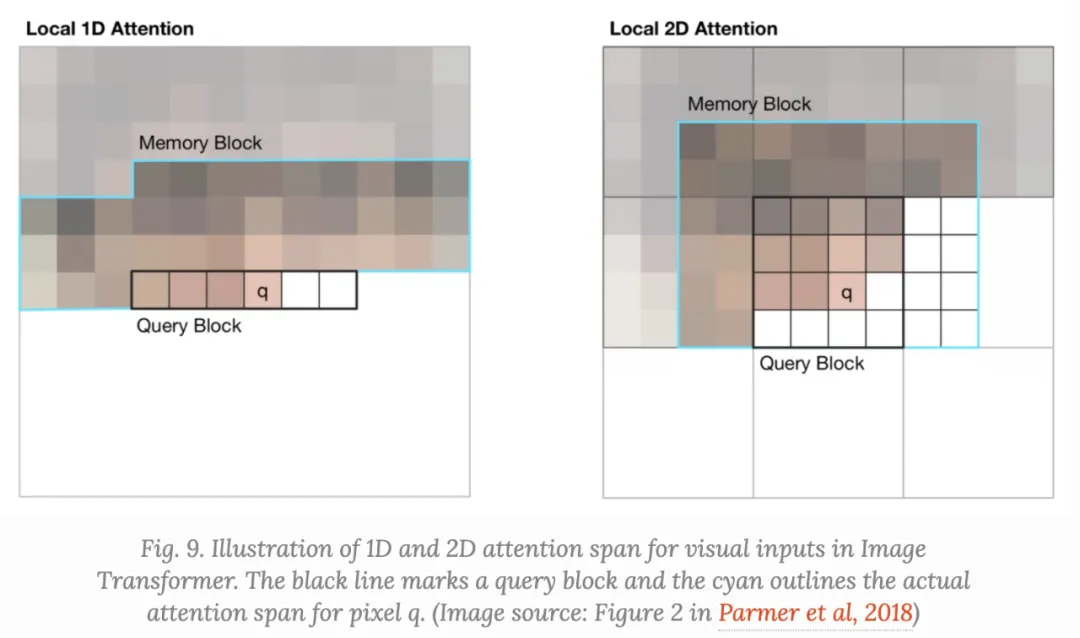
- (1)、1D Local Attention:输入图像按光栅扫描顺序(即从左到右、从上到下)展平。然后将线性化后的图像分割成不重叠的查询块。上下文窗口由与相同的查询块中的像素和在此查询块之前生成的固定数量的附加像素组成。
- (2)、2D Local Attention:图像被分割成多个不重叠的矩形查询块。查询像素可以处理相同内存块中的所有其他像素。为了确保左上角的像素也可以有一个有效的上下文窗口,内存块将分别向上、左和右扩展一个固定的量。
Sentiment Analysis with Bert
上一周课程的回顾,需要动手实践,链接:
1、sentiment-analysis-with-bert
2、https://github.com/marchboy/Getting-Things-Done-with-Pytorch 第八节
Deploy BERT for Sentiment Analysis with Transformers by Hugging Face and FastAPI
模型部署,需动手实践,链接:
1、https://github.com/curiousily/Deploy-BERT-for-Sentiment-Analysis-with-FastAPI
2、https://github.com/marchboy/Getting-Things-Done-with-Pytorch 第九节
RASA DIET
Why use DIET
Large-scale pre-trained language models aren’t ideal for developers building conversational AI applications.
DIET is different because it:
Is a modular architecture that fits into a typical software development work-flow
是适合典型软件开发工作流程的模块化架构
Parallels large-scale pre-trained language models in accuracy and performance
并行大规模预训练语言模型的准确性和性能
Improves upon current state of the art and is 6X faster to train
改进了当前的技术水平,训练速度提高了6倍
How it works?
Dual Intent and Entity Transformer(DIET) as its name suggests is a transformer architecture that can handle both intent classification and entity recognition together. The best thing about DIET is its flexibility. It provides the ability to plug and play various pre-trained embeddings like BERT, GloVe, ConveRT, and so on. So, based on your data and number of training examples, you can experiment with various SOTA NLU pipelines without even writing a single line of code.
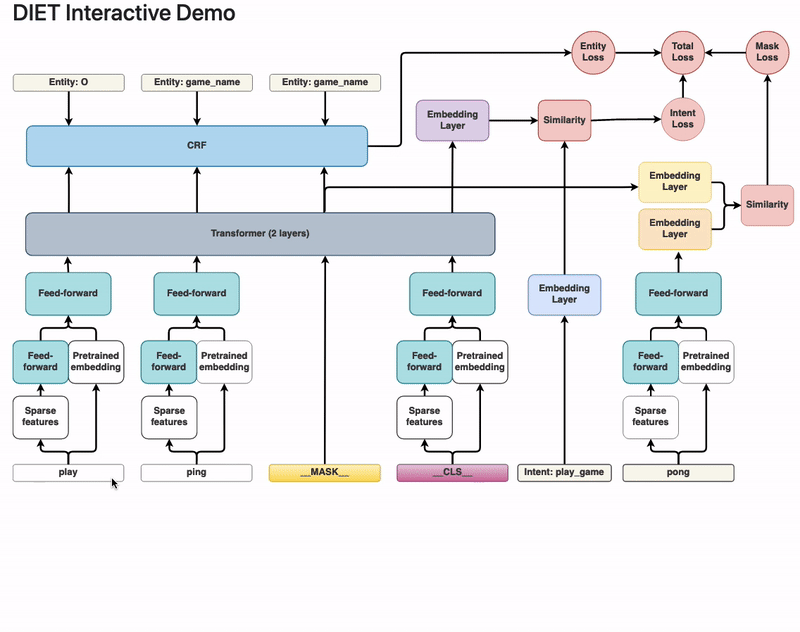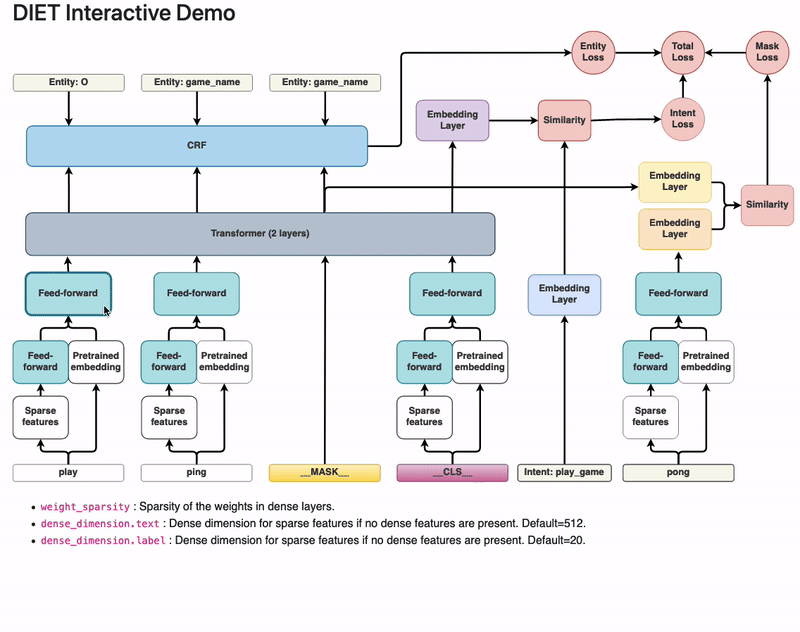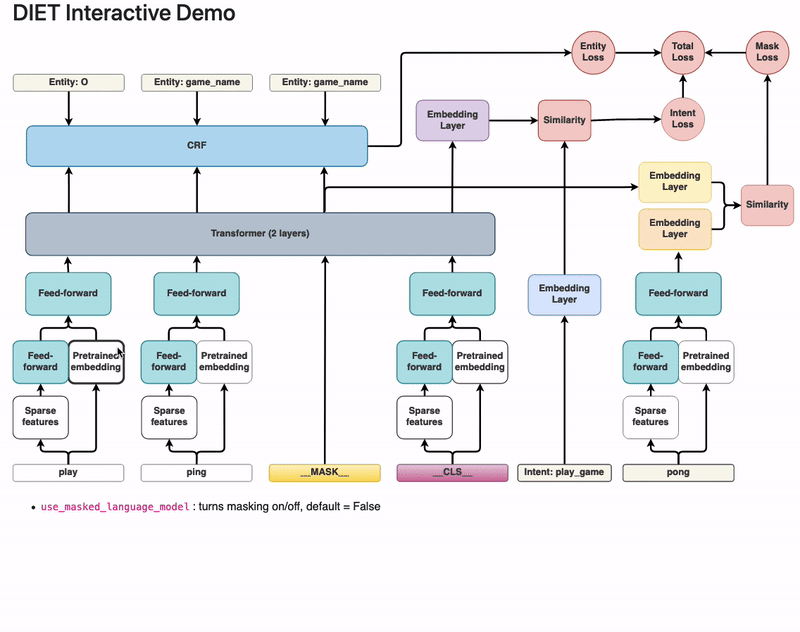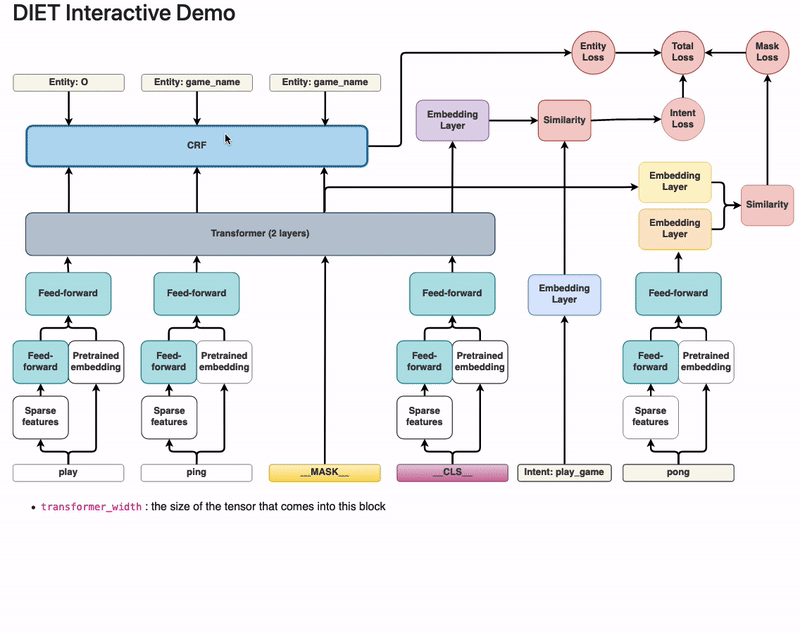
https://zhuanlan.zhihu.com/p/337181983
https://www.yiyibooks.cn/nlp/diet/index.html https://arxiv.org/pdf/2004.09936.pdf视频:
Rasa Algorithm Whiteboard - Diet Architecture 1: How it Works
Rasa Algorithm Whiteboard - Diet Architecture 2: Design Decisions
Why does this Architecture look this way?
Custom ~
类似于乐高玩具,可以自定义各个模块
How to Choose Pipeline?

You already have Intent + Slot!But … which slots do you need?
API
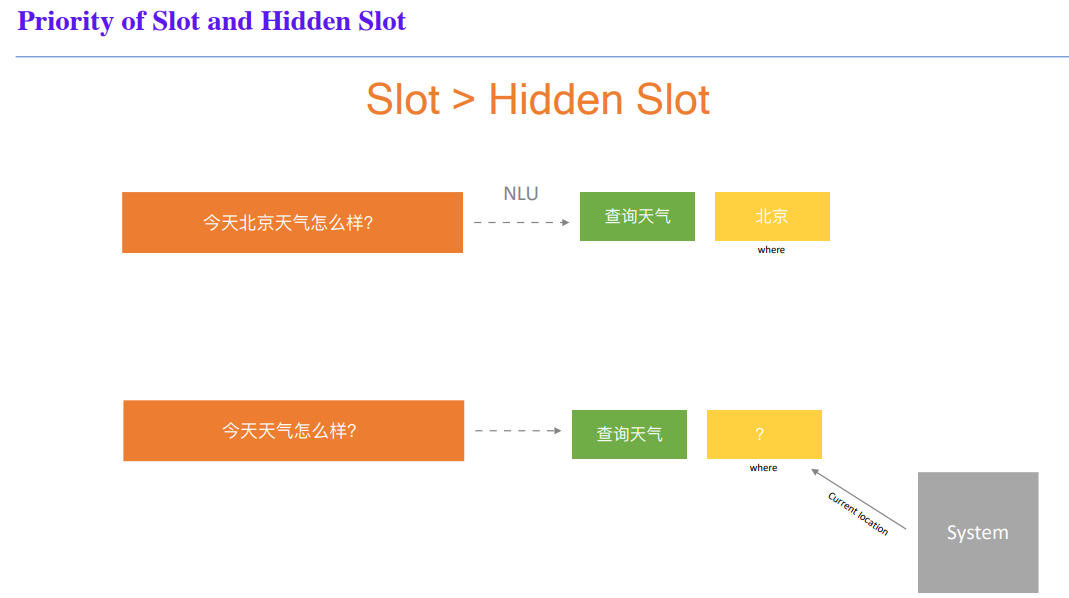
No Slot neither Hidden Slot and How to do with Multi-turn?
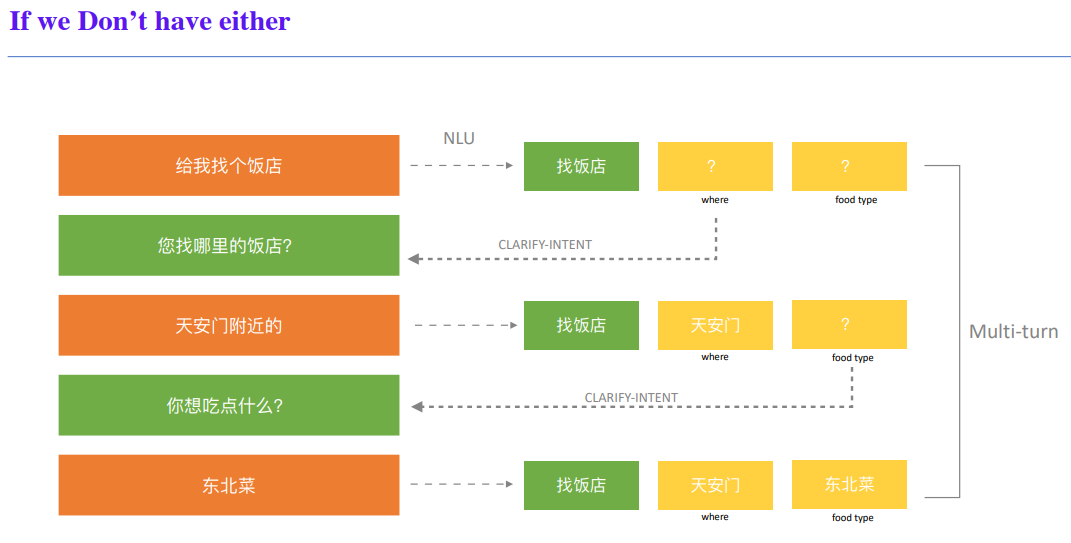
FSM
有限状态机,也称为FSM(Finite State Machine),其在任意时刻都处于有限状态集合中的某一状态。当其获得一个输入字符时,将从当前状态转换到另一个状态,或者仍然保持在当前状态。
任何一个FSM都可以用状态转换图来描述,图中的节点表示FSM中的一个状态,有向加权边表示输入字符时状态的变化。
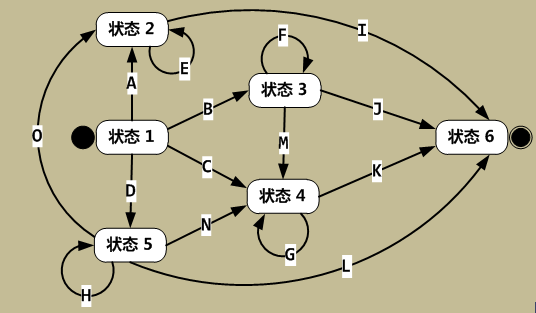
如果图中不存在与当前状态与输入字符对应的有向边,则FSM将进入“消亡状态(Doom State)”,此后FSM将一直保持“消亡状态”。
状态转换图中还有两个特殊状态:状态1称为“起始状态”,表示FSM的初始状态。状态6称为“结束状态”,表示成功识别了所输入的字符序列。
在启动一个FSM时,首先必须将FSM置于“起始状态”,然后输入一系列字符,最终,FSM会到达“结束状态”或者“消亡状态”。
PS:在信息工程,通信技术领域的状态机定义
状态机由状态寄存器和组合逻辑电路构成,能够根据控制信号按照预先设定的状态进行状态转移,是协调相关信号动作、完成特定操作的控制中心。有限状态机简写为FSM(Finite State Machine),主要分为2大类:
第一类,若输出只和状态有关而与输入无关,则称为Moore状态机
第二类,输出不仅和状态有关而且和输入有关系,则称为Mealy状态机
状态机就是状态转移图。举个最简单的例子,人有三个状态:健康,感冒,康复中。触发的条件有淋雨(t1),吃药(t2),打针(t3),休息(t4)。所以状态机就是健康-(t4)->健康;健康-(t1)->感冒;感冒-(t3)->健康;感冒-(t2)->康复中;康复中-(t4)->健康,等等。就是这样状态在不同的条件下跳转到自己或不同状态的图。
状态机可归纳为4个要素,即现态、条件、动作、次态。这样的归纳,主要是出于对状态机的内在因果关系的考虑。“现态”和“条件”是因,“动作”和“次态”是果。详解如下:
①现态:是指当前所处的状态。
②条件:又称为“事件”,当一个条件被满足,将会触发一个动作,或者执行一次状态的迁移。
③动作:条件满足后执行的动作。动作执行完毕后,可以迁移到新的状态,也可以仍旧保持原状态。动作不是必需的,当条件满足后,也可以不执行任何动作,直接迁移到新状态。
④次态:条件满足后要迁往的新状态。“次态”是相对于“现态”而言的,“次态”一旦被激活,就转变成新的“现态”了。
Reference:
4、Using the DIET classifier for intent classification in dialogue

