关于CrossWOZ数据集
第一个大规模的中文跨域“人机交互”任务导向的数据集。
CrossWOZ包含 6K 个对话,102K 个句子,涉及 5 个领域(景点、酒店、餐馆、地铁、出租)。
将对话分成五种类型:单领域 S,多领域 M,多领域加交通 M+T,跨领域 CM,跨领域加交通 CM+T。交通代表了地铁和出租领域,M 和 CM 的区别是有没有跨领域的约束。
此外,语料库包含丰富的对话状态注释,以及用户和系统端的对话行为。
1 | "dialog_action":[ |
更多关于CrossWOZ,参考:
1、CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Datase
Intent Classification
在常见的一个意图的分类情形中,实际还需要处理其他更为复杂的意图识别情形,有:
情形一 NLU中意图和槽位的多样性:
在对话系统的NLU中,意图识别(Intent Detection)和槽位填充(Slot Filling)是两个重要的子任务。其中,意图识别可以看做是NLP中的一个分类任务,而槽位填充可以看做是一个序列标注任务。
在早期的系统中,通常的做法是将两者拆分成两个独立的子任务。但这种做法跟人类的语言理解方式是不一致的,事实上我们在实践中发现,两者很多时候是具有较强相关性的,比如下边的例子:
1.我要听[北京天安门, song] — Intent:播放歌曲
2.帮我叫个车,到[北京天安门, location] — Inent:打车
3.播放[忘情水, song] — Intent:播放歌曲
4.播放[复仇者联盟, movie] — Intent:播放视频
例子1和2中,可以看到同样是“北京天安门”,由于意图的不同,该实体具备完全不同的槽位类型。
例子3和4中,由于槽位类型的不同,导致了最终意图的不同,这往往意味着,在对话系统中的后继流程中将展现出完全不同的行为——-打开网易音乐播放歌曲 or 打开爱奇艺播放电影。
情形二 Multi Intents:
在对话NLU中,可能还会出现一些多意图的情形: 如景点距离我多远,能帮我导航出来吗?
这里就涉及到用户的几个意图:找景点、找距离。
那在做多分类的时候,一般是在网络输出层(Output Layer)上,需要接上一层Softmax activation function;接着输出每一类的概率,针对每一类的概率之后,需要识别每一个分类来判断它是属于0还是1,所以还需要接上一层Sigmoid,并且Loss也不能使用交叉熵了。有:
Softmax激活函数
交叉熵
Sigmoid激活函数
信息熵
情形三 多轮返回(Multi Turn)
包含上下文的信息,需要引入history,例如:
今天天气不好啊,我下午能去做什么呢—-> 去打球、在家打游戏,出去唱K
在此引出BERT框架,大致为:
预料【输入】 —> 分词(Tokenization)—>
CLS、 Tok1、…、Tok N —> BERT —>
C(vector)、 T1、 …、 T N —-> Dense Layer +Activation —> Probalities【输出】
关于Bert
以下摘自论文【BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding】:
BERT is designed to pre-train depp bidirectional represntations from unlabeled text by jointlly conditioning on both left and right context in all layers.
As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-toright language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer.
During fine-tuning, all parameters are fine-tuned.
[CLS] is a special symbol added in front of every input example,
[CLS] 一个全局的向量,放在第一个句子的首位,经过 BERT 得到的的表征向量 C 可以用于后续的分类任务。 [CLS] we must add this token to the start of each sentence, so BERT knows we’re doing classification。
[SEP] is a special separator token (e.g. separating questions/answers).
[SEP] 句子结尾的标记,用于分开两个输入句子,例如输入句子 A 和 B,要在句子 A,B 后面增加 [SEP] 标志。
[UNK] 标志指的是未知字符。
[UNK] BERT understands tokens that were in the training set. Everything else can be encoded using the
[UNK](unknown) token。[MASK] 标志用于遮盖句子中的一些单词,将单词用 [MASK] 遮盖之后,再利用 BERT 输出的 [MASK] 向量预测单词是什么。
摘自【sentiment-analysis-with-bert】
BERT (introduced in this paper) stands for Bidirectional Encoder Representations from Transformers.
BERT(本文介绍)代表来自Transformers的双向编码器表示。
Bidirectional - to understand the text you’re looking you’ll have to look back (at the previous words) and forward (at the next words)
双向-要理解您要查找的文本,您必须向后(在前一个单词处)和向前(在后一个单词处)。
The Transformer reads entire sequences of tokens at once. In a sense, the model is non-directional, while LSTMs read sequentially (left-to-right or right-to-left). The attention mechanism allows for learning contextual relations between words.
Transformer一次读取整个令牌序列。从某种意义上说,该模型是无方向性的,而LSTM则按顺序读取(从左到右或从右到左)。注意机制允许学习单词之间的上下文关系。
BERT was trained by masking 15% of the tokens with the goal to guess them. An additional objective was to predict the next sentence.
BERT通过掩盖15%的tokens来进行训练,目的是猜测它们。另一个目标是预测下一个句子。
Masked Language Modeling (Masked LM)
The objective of this task is to guess the masked tokens. Let’s look at an example, and try to not make it harder than it has to be:
这个任务的目的是猜测被屏蔽的Tokens。让我们看一个例子,尽量不要让它变得比原来更难:
That’s
[mask]she[mask]-> That’s what she saidNext Sentence Prediction (NSP)
Given a pair of two sentences, the task is to say whether or not the second follows the first (binary classification). Let’s continue with the example:
Input =
[CLS]That’s[mask]she[mask]. [SEP] Hahaha, nice! [SEP]Label = IsNext
Input =
[CLS]That’s[mask]she[mask]. [SEP] Dwight, you ignorant[mask]! [SEP]Label = NotNext
The training corpus was comprised of two entries: Toronto Book Corpus (800M words) and English Wikipedia (2,500M words).
While the original Transformer has an encoder (for reading the input) and a decoder (that makes the prediction), BERT uses only the decoder.原始的Transformer具有一个编码器(用于读取输入)和一个解码器(用于进行预测),而BERT仅使用解码器。
BERT is simply a pre-trained stack of Transformer Encoders. How many Encoders? We have two versions - with 12 (BERT base) and 24 (BERT Large).
Is This Thing Useful in Practice?
The BERT paper was released along with the source code and pre-trained models.
The best part is that you can do Transfer Learning (thanks to the ideas from OpenAI Transformer) with BERT for many NLP tasks - Classification, Question Answering, Entity Recognition, etc. You can train with small amounts of data and achieve great performance!
发表BERT的动机(Motivation):
1、大量数据,没有标签
2、当前word embedding 模型能力不够强大,有较多的局限性
3、没有考虑上下文信息,word2vec没有根据上文来生成向量
4、问答中长文本的依赖,传统的RNN会导致梯度的消失(LSTM可以缓解,但也会发生梯度消失)
5、迁移学习能否进一步推广应用,做fine turn的工作
Basic idea
随机masks words in sentence and predict them
Transformer architecture
Next sentence prediction
严格来说,Bert是一种训练策略,不是新的架构设计。
BERT-DATA
WordPieces instead of words, (eg.playing-> play+ ing)它的实现方式是是一种叫BPE(Byte-Pair Encoding)的双字节解码。
1、减少词汇的数量
2、增加每一个单词的样本数量
3、避免OOV
WordPieces带来的问题:
probability—-pro+ ##bali + ##lity
如果bali被masked,则很容易预测到probability这个单词,在中文中亦是如此。
解决方案:Whole Word Masking

补充点:
1、关于whole word piece(WWP),它是对BERT的一个很有效的改进
中文全词覆盖(Whole Word Masking)BERT的预训练模型
2、BPE
现在基本性能好一些的NLP模型,例如OpenAI GPT,google的BERT,在数据预处理的时候都会有WordPiece的过程。WordPiece字面理解是把word拆成piece一片一片,其实就是这个意思。
WordPiece的一种主要的实现方式叫做BPE(Byte-Pair Encoding)双字节编码。
BPE的过程可以理解为把一个单词再拆分,使得我们的此表会变得精简,并且寓意更加清晰。
比如”loved”,”loving”,”loves”这三个单词。其实本身的语义都是“爱”的意思,但是如果我们以单词为单位,那它们就算不一样的词,在英语中不同后缀的词非常的多,就会使得词表变的很大,训练速度变慢,训练的效果也不是太好。
BPE算法通过训练,能够把上面的3个单词拆分成”lov”,”ed”,”ing”,”es”几部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量。
BERT 中的tokenizer和wordpiece和bpe(byte pair encoding)分词算法
3、Transformer-XL
Transformer-XL的依存关系比RNN长80%,比原始Transformer长450%,在短序列和长序列上均具有更好的性能,并且在评估期间比原始Transformer快1800倍以上。
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
关于Attention
Attention的思想如同它的名字一样,就是“注意力”,在预测结果时把注意力放在不同的特征上,核心逻辑就是从【关注全部】 到 【关注重点】。
在视觉图像、文本任务中, Attention机制是将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
优点:
参数少:模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
速度快:Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
效果好:在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
Attention原理
attention 引入 Encoder-Decoder 框架下,完成机器翻译任务的大致流程。
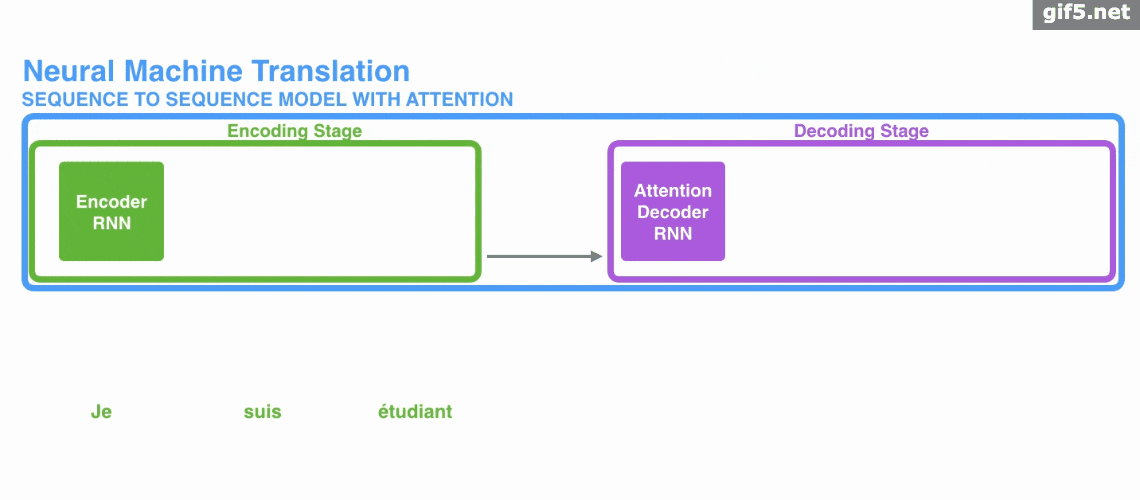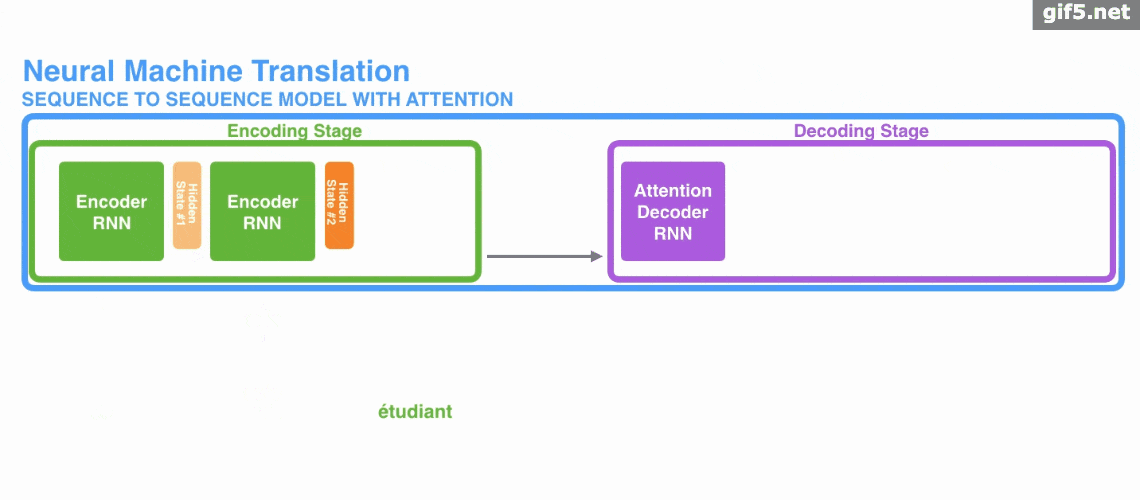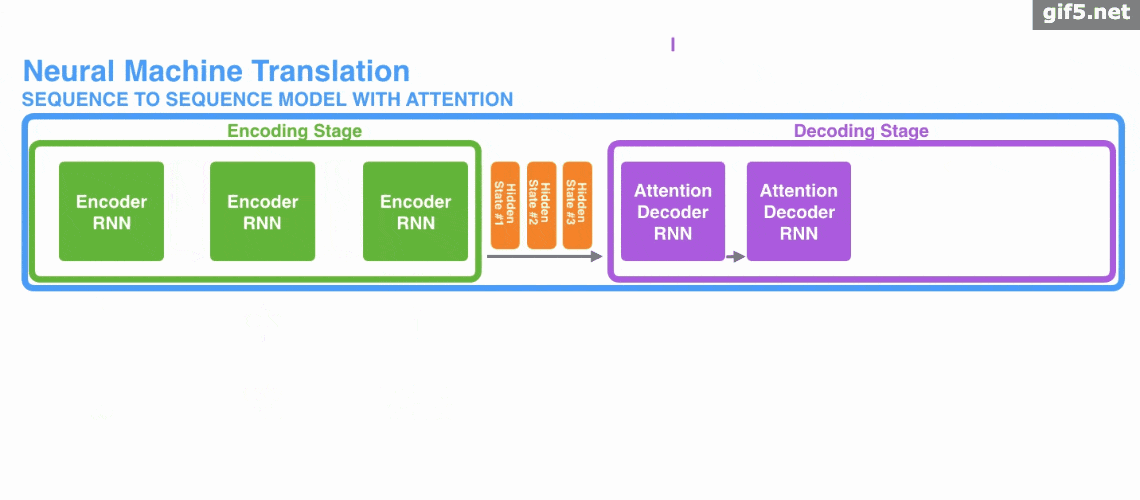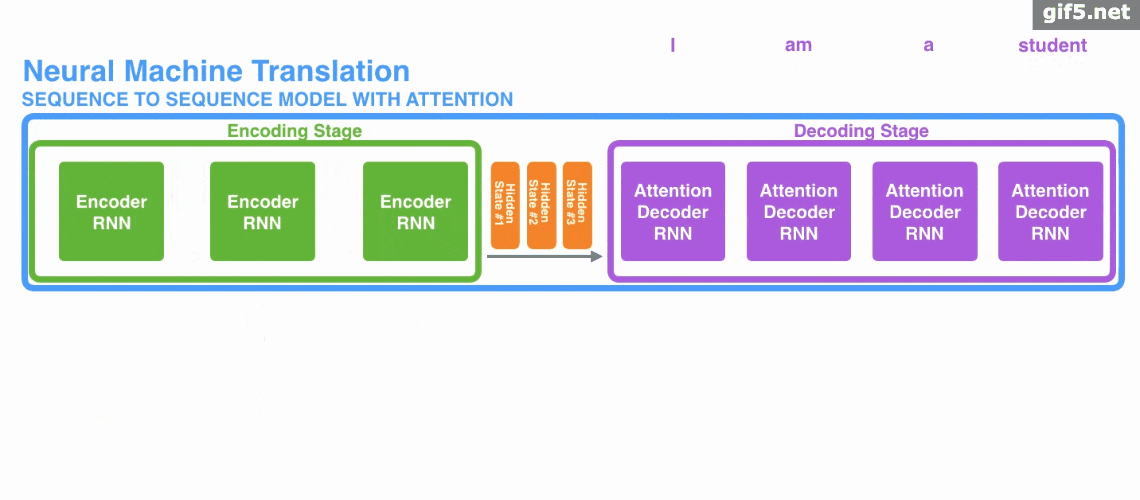
Attention基本原理的基本步骤:
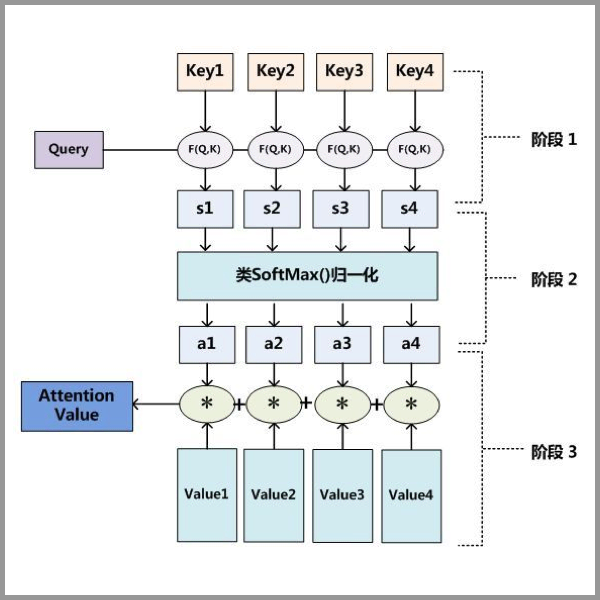
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
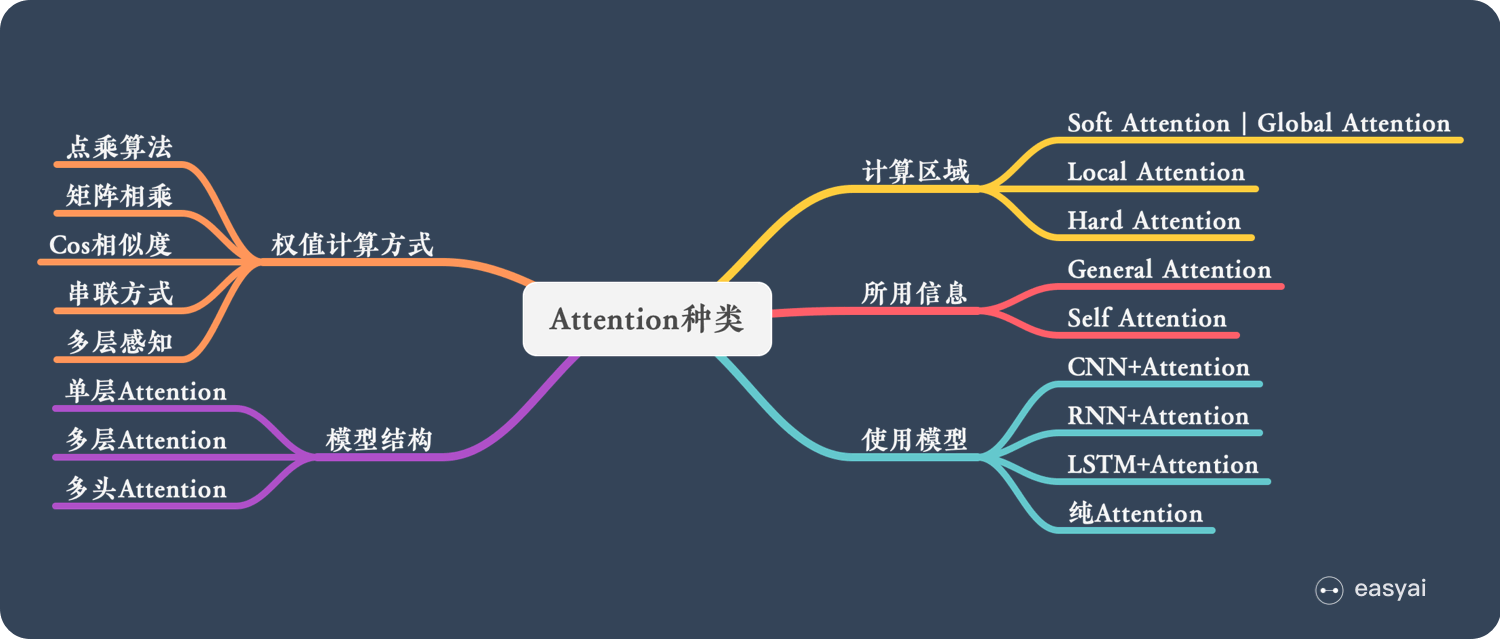
Attenttion 类型:
关于Transformer
![]()
参考老师PPT32-45页
参考:
1、论文详解Transformer (Attention Is All You Need)
2、Transformer 一篇就够了(一): Self-attenstion
3、Transformer 一篇就够了(二): Transformer中的Self-attenstion
4、技术细节 模型优化之Layer Normalization
5、Multi-label Text Classification using BERT – The Mighty Transformer
NLU: Slot Extraction
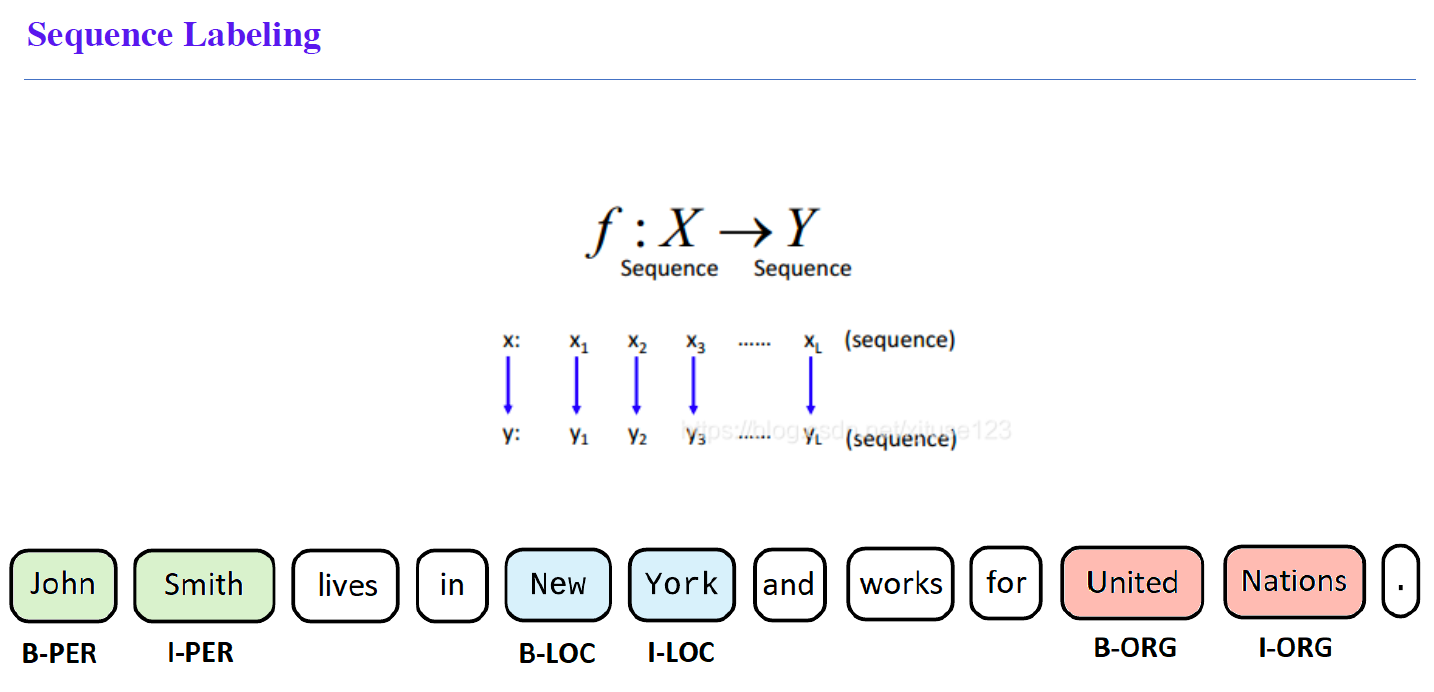
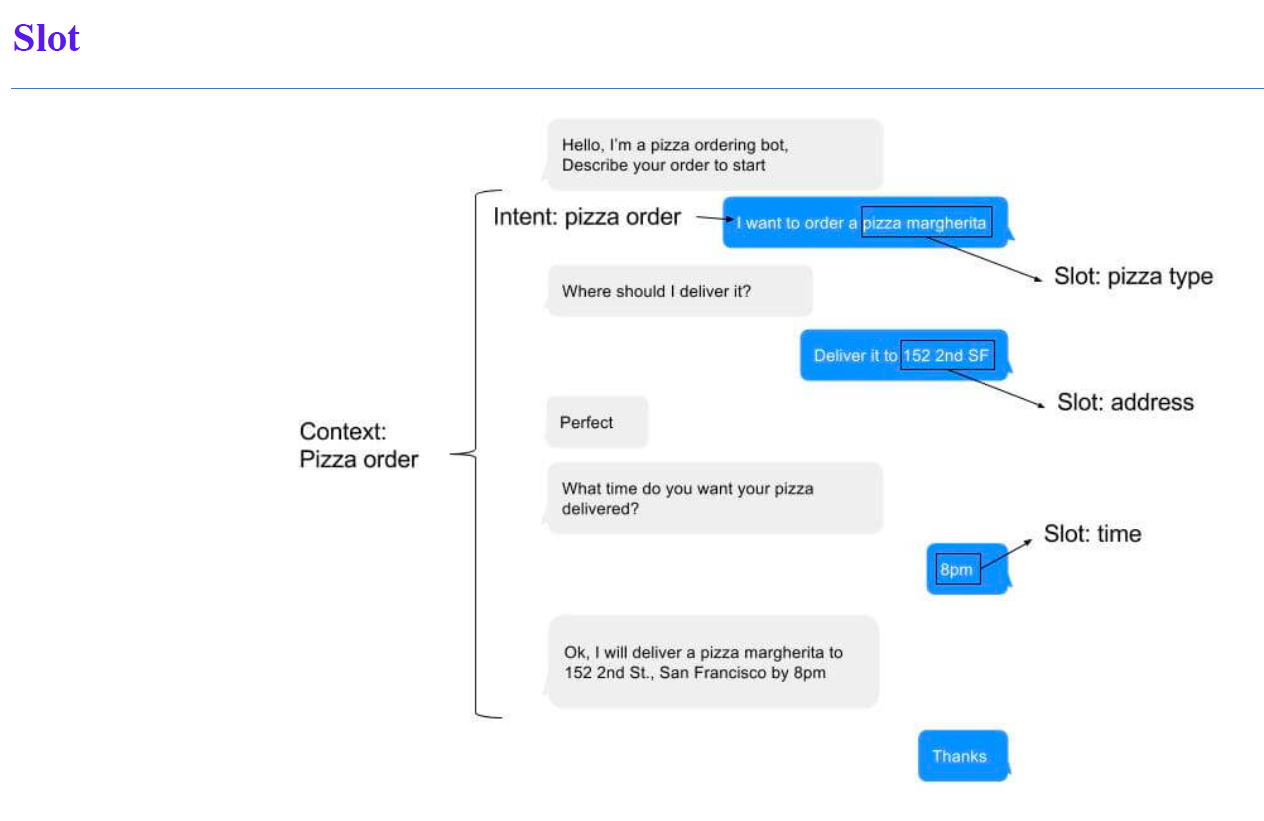
NLU: Joint Intent-Slot extraction
Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling(2016)
基于注意力的编码器-解码器神经网络模型最近在机器翻译和语音识别中显示出令人鼓舞的结果。在这项工作中,我们提出了一种基于注意力的神经网络模型,用于联合意图检测和slot filling,这对于许多语音理解和对话系统都是至关重要的步骤。与机器翻译和语音识别不同,对齐在slot filling中是显式的。我们探索将对齐信息整合到编码器-解码器框架中的不同策略。从编码器-解码器模型中的注意力机制中学习,我们进一步建议将注意力引入基于对齐的RNN模型。这种关注为意图分类和slot filling预测提供了更多信息。我们的独立任务模型在ATIS任务上实现了最优的意图检测错误率和slot fillingF1分数。与独立任务模型相比,我们的联合训练模型在意图检测上进一步获得了0.56%的绝对误差(相对值23.8%的相对误差),在slot filling上获得了0.23%的绝对增益。
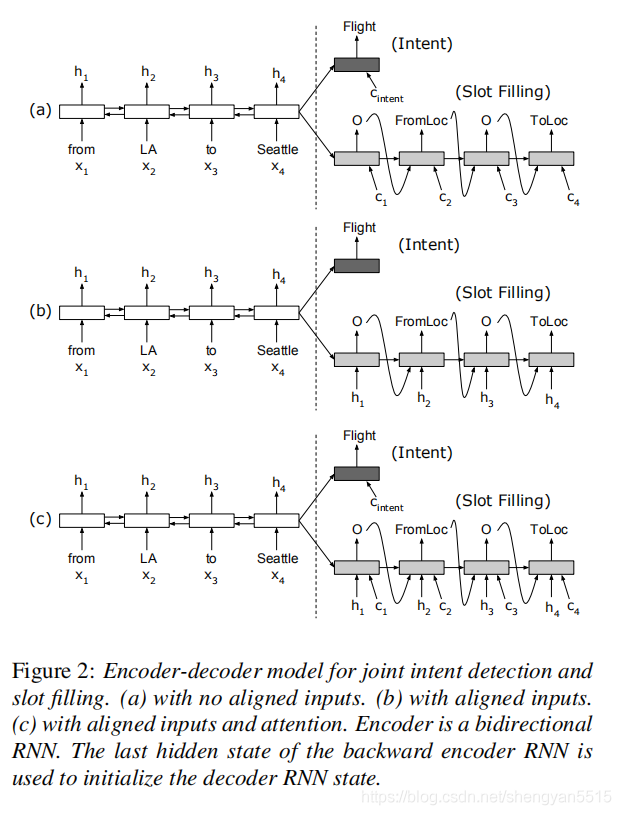
参考:Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling论文笔记
Slot-Gated Modeling for Joint Slot Filling and Intent Prediction(2018)
基于注意力的递归神经网络模型用于联合意图检测和插槽填充,具有最先进的性能,同时具有独立的注意力权重。考虑到插槽和意图之间存在很强的关系,本文提出了一种插槽门,其重点是学习意图和插槽注意向量之间的关系,以便通过全局优化获得更好的语义框架结果。实验表明,与基准ATIS和Snips数据集上的注意力模型相比,我们提出的模型显著提高了句子级语义框架的准确率,相对注意度模型分别提高了4.2%和1.9%。
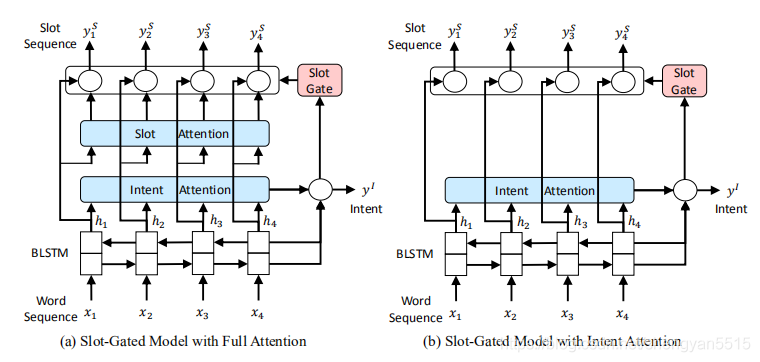
笔记:Slot-Gated Modeling for Joint Slot Filling and Intent Prediction论文笔记
BERT for Joint Intent Classification and Slot Filling(2019)
意图分类和slot filling是自然语言理解的两个基本任务。它们经常遭受小规模的人工标签训练数据的困扰,导致泛化能力差,尤其是对于稀有单词。最近,一种新的语言表示模型BERT(来自Transformers的双向编码器表示)有助于在大型未标记的语料库上进行预训练深层的双向表征,并在处理完各种自然语言处理任务后创建了最新的模型简单的微调。但是,在探索BERT以获得自然语言理解方面并没有付出很多努力。在这项工作中,我们提出了一个基于BERT的联合意图分类和slot filling模型。实验结果表明,与基于注意力的递归神经网络模型和slot-gated模型相比,我们提出的模型在多个公共基准数据集上的意图分类准确性,slot filling F1和句子级语义准确性都有了显着提高。
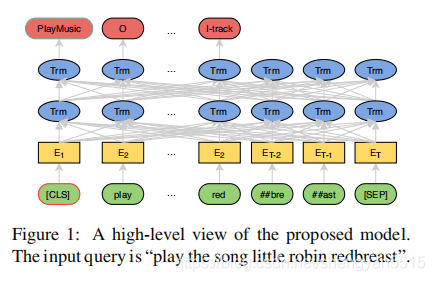
笔记:BERT for Joint Intent Classification and Slot Filling论文笔记

