为什么要数据建模
为什么要数据建模?
这是一个互联网的时代,也是大数据的时代,数据的价值不言而喻。虽然大家都知道数据很重要,但如果数据不能得到很好应用,那么数据就没有价值,数据建模就是为了能够将数据的价值更好的挖掘出来 ,所进行的一系列工作。
数据建模本身是一种组织、分析、存储、应用数据的方法论,尽然是一种方法论,那么就有衡量好坏的标准:性能、成本、效率、质量。因此,数据建模的工作,就是围绕这四个指标做出最优解而进行的努力。
数据建模是数据研发岗位的核心内容,是数据采集 - 数据建模 - 数据开发 - BI应用这个研发链条上的关键步骤。
数据建模的日常工作,就是通过宏观模型 + 分层模型,做好标准化的模型建设,并依赖报表、接口等产品服务,输出数据价值。因此,掌握核心的数据建模理论,就是数据研发工程师的核心竞争力。
好在,数据建模的理论并不难理解,很容易学会。但困难的是,想要把这套理论应用的的新应用,需要非常多的训练才能掌握。尤其对于互联网行业来讲,数据量足够大、业务足够复杂,才能练出足够好的数据建模师来。
数据建模理论
让我们先来看看基础的数据建模理论。
由于在变化快速的商业世界里,业务形态多种多样,为了能够更有针对性的进行数据建模,经过长时间的摸索,业界逐步形成了数据建模的四部曲:业务建模->领域建模->逻辑建模->物理建模。简单讲,就是明确具体业务,抽象实体和关系,结合具体的建模方法,确定所有关键成分和属性,最后建数据表进行数据的存储和计算。
目前数据建模的方法论有两大阵营,一个是基于关系型数据库理论设计出来的,比如基于3NF的范式建模。虽然目前也有不少非关系型数据库以及不少半结构化和非结构化数据。但将半结构化/非结构化数据转化为结构化数据,然后再利用关系型数据库处理仍然是一种通用的主流数据处理方案。另一个是基于数据仓库之父Bill Inmon提出的维度建模理论,是从全企业的高度利用实体关系来对企业业务进行描述。
先讲讲范式建模,包括E-R模型、DATA Vault模型和Anchor模型。
E-R模型是典型的范式数仓建模,满足3NF,通过实体关系来描述企业业务之间的关系,通常是面向整体的,而不是面向单个业务过程来进行建立。作为一种标准的数据建模方案,E-R模型的数据一致性和扩展性都比较好,且经得起时间的考验,但在大数据多分析型场景诉求下,查询性能和便捷度都存在一定的不足,因此在实际业务中,往往只应用在DWD层。
DATA Vault模型是ER模型的衍生版本,将实体的描述部分拆分开来,当作单独的一个部分存在。DATA Vault模型不能直接面向业务进行数据分析决策,需要关联处理之后才能进行相应数据指标的统计,它的扩展性更好,但同时性能和便捷度更差。
Anchor模型是对DATA Vault更进一步的范式化处理,扩展性更好,但可分析性能更差。
再讲讲维度建模。
维度模型主要围绕一个确定的业务过程展开,先确定好粒度和维度属性,再计算具体的指标。维度模型的典型结构是星型模型,也可能演变为雪花模型。经过互联网行业多年的探索,证实设计出好的维度模型比E-R模型更简单快速,但是缺点也比较明显,由于冗余太多维度属性,数据一致性和扩展型都相对较差,对过快业务变化的场景并不友好。由于维度建模更适合大数据面向OLAP场景下的数据建模方案,因此在实际业务中,通常应用在中间层DWS或ADS上层的数据集市。
以上内容,网上有大量的书籍和文章详细介绍,这里推荐阅读两本就足够了,一本是Kimball的原书《数据仓库生命周期工具箱》、一本是《阿里巴巴大数据实践之路》。
数据建模中的宏观模型
讲完了基础的数据建模理论,再来看看日常工作,先讲一下宏观模型。
数据仓库的定义是什么?是一个面向“主题”的、集成的、相对稳定的、反映历史变化的“数据集合”,用于支持管理决策。数据仓库的指导思想是:以“维度建模”为基础构建总线矩阵,按照“数据域”和“业务过程”进行“主题模型”设计,构建一致性的维度和事实。主题模型是指数仓使用用户所重点关心大脑内容,是一个商业领域所涉及的所有分析对象,如“销售分析”、“用户分析”,通常横跨多个业务系统或者数据系统。主题域下面可以有多个主题,主题还可以划分成更多的子主题。
把一个数据仓库做了横向的切分,或者说把企业的多个业务横向切分成不同的主题模型,又可继续细分为不同的子域,因此形成了一个具有公共前缀的树形结构,这个公共前缀通过命名规范体现出来,这也是为什么我们要强调表的命名规范的原因。
如下图所示,基础DB或者是Log日志,通过不同的主题进行聚集,最后输出到同一个主题域中。
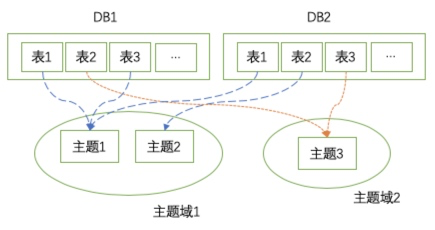
从宏观的顶层设计来看,我们的数据模型应该是面向主题设计的,由于业务体系庞大,为了能够更加清晰的区分数据表的职责,我们将主题模型设计将细分为数据域和业务过程。
数据域:将业务过程或维度进行抽象,即“业务过程”或“维度”的集合,数据域还可划分多级子域。数据域是指面向业务分析,将业务过程进行抽象的集合。数据域需要抽象提炼,并且长期维护和更新,但不轻易变动。数据域的划分对于维度建模理论在层次数仓建模落地上有重要意义,一般根据业务过程相似性将同类业务数据划分到一个数据域中,底层数据的加工都会聚焦在同一个数据域中进行,在上层应用时才会加工跨数据域的数据模型。
业务过程:指企业活动中一个不可拆分的的行为事件,如下单、支付、退款等行为事件。
因此,我们可以简单的认为,主题模型 = 数据域 + 业务过程。
我们通常所做的模型设计,宏观层面上,就是合理的划分数据域和业务过程,而这种划分的结果是以表名的形式体现出来的,因此合理的数仓结构中,通过表名便应该能够清晰的分辨出这张表所属的数据域和业务过程,这与工程上所强调的“代码整洁之道”有异曲同工之妙。
数据建模中的分层设计
划分清楚了大的概念,接下来讲实际开发,最重要的是分层设计,这也是维度建模的灵魂,也是互联网公司经过过年的探索,得出的最佳实践。
在介绍分层之前,讲几个基本的概念。

接下来讲分层的内容。
数据分层 = ODS + CDM(DIM + DWD + DWS)+ ADS,当业务不复杂时,也可以忽略某些层,比如DB设计的足够优秀且业务比较简单,ODS就可以不用建设。
ODS面向ETL过程设计,通常不改变数据的内容,重点考虑数据如何及时可靠的同步过来。
ODS作为原始数据存储层,建议保留全部的数据原始记录,留底而不做任何清洗操作。ODS层对接的系统侧数据一般为明细数据,如果不是实时数据,调度周期一般为日调度或小时调度。对于数据的同步方式,ODS只记录会发生更新变更的数据,例如累计快照事实表、多事务事实表,建议采用时间上的全量同步;不会发生更改删除的数据,例如事务事实表,建议采用时间增量同步。ODS表的保留周期,一般为全量7天、增量永久。
CDM = Common Data Model,该层不面向产品需求开发,而是针对业务过程的抽象和定义,是数据模型的核心层,一般需要非常严格的规范管理,每次修改理论上都需要进行CodeReview。
DIM作为维表的概念,依据维度建模理论,数据只来自于ODS层,可以做一定加工处理操作。DIM表的调度周期一般为日调度,同步DB全量的快照数据,通常不建议采用增量进行同步。由于是快照表,因此建议永久保留,如果是拉链表则建议保留7天。DIM表有一些额外的考虑因素,即是否缓慢变化维度(选择快照还是拉链需要根据变化频次和业务场景来确定),如果维度存在层次关系,可以通过_ext或者是_tree或者是_graph的后缀进行标注。
DWD作为数据仓库明细层,建设思路主要围绕事务事实表、多事务事实表、累计快照事实表等的明细类表进行建设,对于多个事务事实表可以进行合并为多事务事实表,在各个业务域中结合业务过程选择一个应用较为通用的粒度建立一张明细宽表,同时还需要进行原始数据的清洗工作。DWD表的调度周期一般为日调度,时间上建议全量快照保留,少部分采用增量(主要考虑数据是否发生修改或删除,若存在则需要使用全量)。保留周期同样为全量7天、增量永久。如果有清洗数据的需求,通常做在DWD层,而退化部分维度属性,杂项维度、行为维度、微型维度等直接退化在事实表中,对于明细宽表会考虑冗余部分常用属性提升查询效率。
DWS作为数据仓库服务层,考虑建设完善的数据服务体系与数据集市,统一指标口径,主要存放周期快照事实表、聚集型事实表等汇总类型指标数据表,并且根据是否跨数据域分为两个部分进行建设。统计周期上,DWS与DWD和ODS不同,统计周期通常为:1d(最近一天)、nd(最近n天)、cm(自然月)等方式,因此需要设定通用的规范,与ODS/DWD进行区分。DWS层不存在时间上的全量,只能根据汇总的维度进行周期统计。DWS分为跨数据域和不跨数据域两类汇总表,在同一个业务过程中进行指标汇总计算可以确保数据维度的统一且高效产出,但由于DWS沉淀不足,对上游应用使用不友好,如果都放在ADS进行跨业务过程融合会过于臃肿,因此考虑在DWS进行同一业务过程内汇总的同时,也沉淀一部分通用的跨业务过程汇总表。
ADS是面向应用、服务、需求而开发,命名规范不会限定的很严格,因为存在很多手工数据这种无法标准化的情况,但ADS需要严格的限定依赖深度,防止设计的太复杂导致维护成本很高。
ADS作为应用数据存储层,建设思路是根据业务具体诉求,提供数据服务,公共通用指标尽量从DWS层获取,明细数据透出或其他业务可以从DWD层获取,不建议直接从ODS层获取数据。ADS尽量展示完整的原子指标(例如:有今年花费和去年花费两个指标,应用性能满足的情况下,同比指标可不提供)。
数据建模的标准化
标准化是数据建模非常重要的一步,有道是:“如果数据都是错误的,那么业务如何做出正确的决策呢?”由于数据离不开人的开发,而人通常都是会犯错误的,因此如果标准化做的不好,不光做出来的数据容易出错,而且很容易背锅。
那么数据建模如何标准化?如果有五点:
第一点,数据表的命名是标准的。比如:分层数据域二级数据域业务过程业务描述主键统计周期_刷新周期,通常没有绝对的标准,只有相对的标准。如果数据表的命名规范做的好,不用看注释,其他人都能直接用。
第二点,表指标定义是标准的,无二义性的。表的字段通常包含三个部分:实体&属性、派生指标、时间定义,实体代表DWS和ADS的统计粒度,其属性是从我们的维表中关联出来的;派生指标,是基于原子指标、业务限定等组合出来的;时间定义,通常是天、小时、分钟等。数仓标准化的程度,很大一部分就是看派生指标是否规范、是否统一,很多公司做的“指标库”,本质就是做表指标定义的标准化。
第三点,模型中语料是不断完善的。前面两点中,表和字段都会拆解成最小粒度了,数仓模型针对每个最小粒度都进行了定义,后续的工作中,表命名、字段命名、字段口径都应该从这些模型中能够取出来。
第四点,数据质量是有保障的。
第五点,通过数据来保障模型的规范性。还是那句话,人都是会犯错误的,那么用数据来治理数据,并做成工具天天提醒你,是目前大公司比较统一的思路。参考笔者之前的文章:《数据资产治理概要:用数据来治理数据》。
数据建模中的应用价值
我们构建的数据模型实际上是一种信息流,从明细 -> 轻度汇总 -> 高度汇总的链路,细节逐渐消失,携带的信息量逐渐减少。在明细我们可以看到业务细节,在汇总我们只能看到一些结论性的数据,那么底层的模型设计对外其实是不可见的,那么我们通过高度汇总的数据怎么透传数据价值呢?
其中一种方式,是做数据中台,提供数据产品、数据服务和其他一些数据基础设施,即丰富数据的应用场景可以带来较大的增量价值。
另外一种方式,是做基于数据的业务中台,提供一些对业务场景的洞察。单独的数据模型其实很难产生价值,通常需要配合其他的一些业务场景,来产生增量的价值。
参考:数据建模理论、设计和实践

