Out of Vocabulary
why&what is OOV
未登录词就是训练时未出现,测试时出现了的单词。在自然语言处理或者文本处理的时候,我们通常会有一个字词库(vocabulary)。这个vocabulary要么是提前加载的,或者是自己定义的,或者是从当前数据集提取的。假设之后你有了另一个的数据集,这个数据集中有一些词并不在你现有的vocabulary里,我们就说这些词汇是Out-of-vocabulary,简称OOV。
For example, words such as “tensor” and “tensor” are present in the vocabulary of Word2Vec. But if you try to get embedding for the compound word “tensorflow”, you will get an out of vocabulary error.
- Typo(排版错误,文本里面存在错别字造成的oov)
- Different Vocabularies(不同的词汇表,词不在你来做训练的语料库中、新词的产生并没有添加到你训练的语料库中)
- new words are being created every second(每时每刻都在产生新的词汇)
- you cannot afford to annotate too many data(不能注解太多的词汇)
Solutions
Spell check(过滤掉错误的单词)
Ignore(忽略,这种方法不常用)
UNK work(变成默认词(UNK work,可以在一定程度上缓解oov的问题,但是很多重要的词这样做后都会变成默认词,不太合适 )
This solution is to reserve a dimension in feature space, it may eliminate some impact of OOV word, but very limited. Especially the OOV word plays an important role in the NLP task, e.g. some positive and negative words are OOV words in sentiment analysis.
这种解决方案是在特征空间中保留一个维度,它可能会消除OOV词的一些影响,但非常有限。特别是面向对象词在自然语言处理中起着重要的作用,如一些积极词和消极词在情感分析中都属于面向对象词。
Enlarge Vocabulary(速度下降,会造成数据分布不均)
Individual Characters(把单词切开,将词转换成字符(将每个token变换成字符进行切割,再根据字符拼接,这样会丢失句法和语义信息)
subword(介于token和character方法,对词频低的词不太友好)
Byte Pair Encoding:BPE(根据词频确定留哪些subword)
word piece
unigram language model(看下ppt中的步骤)。
PGN网络(重点难点,参考一下 https://www.cnblogs.com/monkeyT/p/12337556.html)
Subword
sub-word generation
For a word, we generate character n-grams of length FROM n to m(n<m) present in it.
因为可能有大量唯一的n-gram,所以我们应用哈希来限制内存需求。每个字符n-gram被哈希为1到B之间的整数。
Byte Pair Encoding(BPE)
1、准备⾜够大的训练语料
2、确定期望的subword词表大小
3、将单词拆分为字符序列并在末尾添加后缀“ </ w>”,统计单词频率。 本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w </ w>”:5
4、统计每⼀个连续字节对的出现频率,选择最⾼频者合并成新的subword
5、重复第4步直到达到第2步设定的subword词表大小或下⼀个最⾼频的字节对出现频率为1
WordPiece
1、准备⾜够大的训练语料
2、确定期望的subword词表大小
3、将单词拆分成字符序列
4、基于第3步数据训练语⾔模型
5、从所有可能的subword单元中选择加⼊语⾔模型后能最⼤程度地增加训练数据概率的单元作为新的单元
6、重复第5步直到达到第2步设定的subword词表⼤⼩或概率增量低于某⼀阈值
https://huggingface.co/transformers/_modules/transformers/tokenization_bert.html#BertTokenizer
Unigram Language Model
1、准备⾜够⼤的训练语料
2、确定期望的subword词表⼤⼩
3、给定词序列优化下⼀个词出现的概率
4、计算每个subword的损失
5、基于损失对subword排序并保留前X%。为了避免OOV
6、重复第3⾄第5步直到达到第2步设定的subword词表⼤⼩或第5步的结果不再变化
Pointer-Generator Network
文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要。按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文。生成式摘要根据原文,允许生成新的词语、原文本中没有的短语来组成摘要。
指针生成网络属于生成式模型。
仅用Neural sequence-to-sequence模型可以实现生成式摘要,但存在两个问题:
1、 可能不准确地再现细节, 无法处理词汇不足(OOV)单词;
2、 倾向于重复自己。
原文是(they are liable to reproducefactual details inaccurately, and they tendto repeat themselves.)
指针生成网络(Pointer-Generator-Network)从两个方面进行了改进:
1. 该网络通过指向(pointer)从源文本中复制单词,有助于准确地复制信息,同时保留通过生成器产生新单词的能力;
2. 使用coverage机制来跟踪已总结的内容,防止重复。
接下来从下面几个部分介绍Pointer-Generator-Network原理:
1、Baseline sequence-to-sequence;
2、Pointer-Generator-Network;
3、Coverage Mechanism。
Baseline sequence-to-sequence
Pointer-Generator Networks是在Baseline sequence-to-sequence模型的基础上构建的,我们首先Baseline seq2seq+attention。其架构图如下:
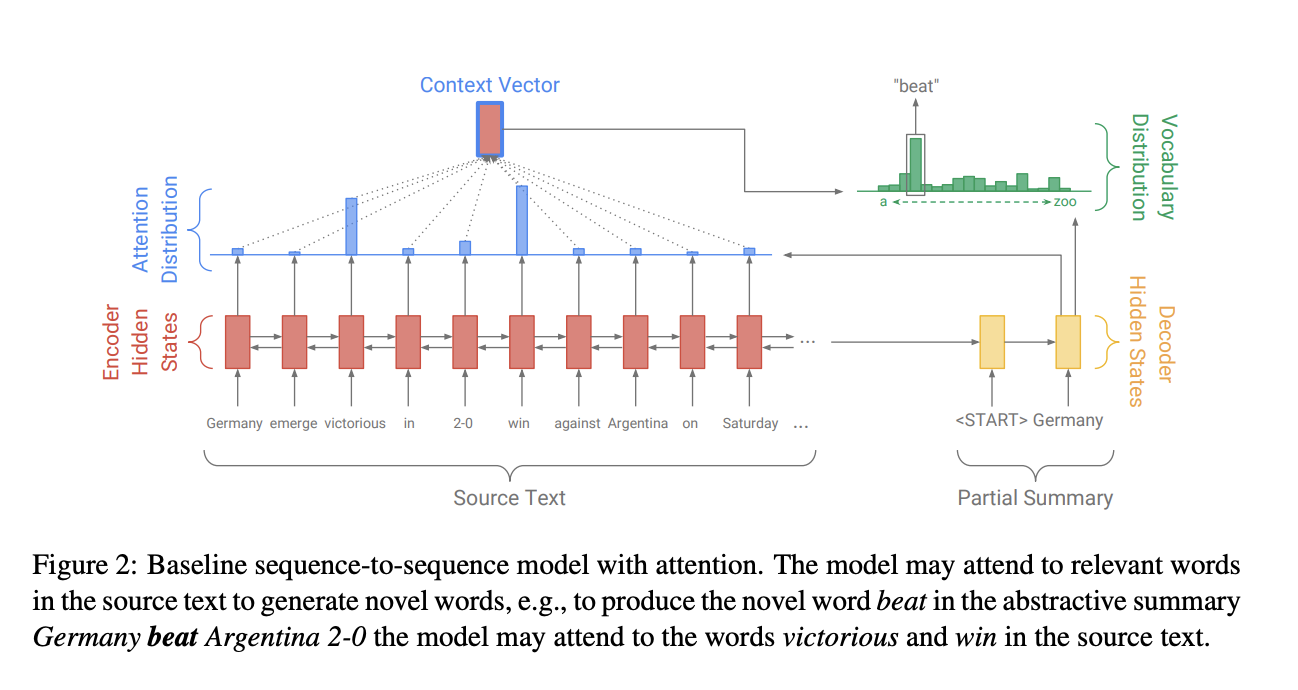
该模型可以关注原文本中的相关单词以生成新单词进行概括。比如:模型可能注意到原文中的“victorious”和“ win”这个两个单词,在摘要”Germany beat Argentina 2-0”中生成了新的单词beat 。
Seq2Seq的模型结构是经典的Encoder-Decoder模型,即先用Encoder将原文本编码成一个中间层的隐藏状态,然后用Decoder来将该隐藏状态解码成为另一个文本。Baseline Seq2Seq在Encoder端是一个双向的LSTM,这个双向的LSTM可以捕捉原文本的长距离依赖关系以及位置信息,编码时词嵌入经过双向LSTM后得到编码状态$h_i$。在Decoder端,解码器是一个单向的LSTM,训练阶段时参考摘要词依次输入(测试阶段时是上一步的生成词),在时间步$t$得到解码状态$s_t$。使用$h_i$和$s_t$得到该时间步原文第$i$个词注意力权重。
Pointer-Generator-Network
原文中的Pointer-Generator Networks是一个混合了 Baseline seq2seq和PointerNetwork的网络,它具有Baseline seq2seq的生成能力和PointerNetwork的Copy能力。该网络的结构如下:
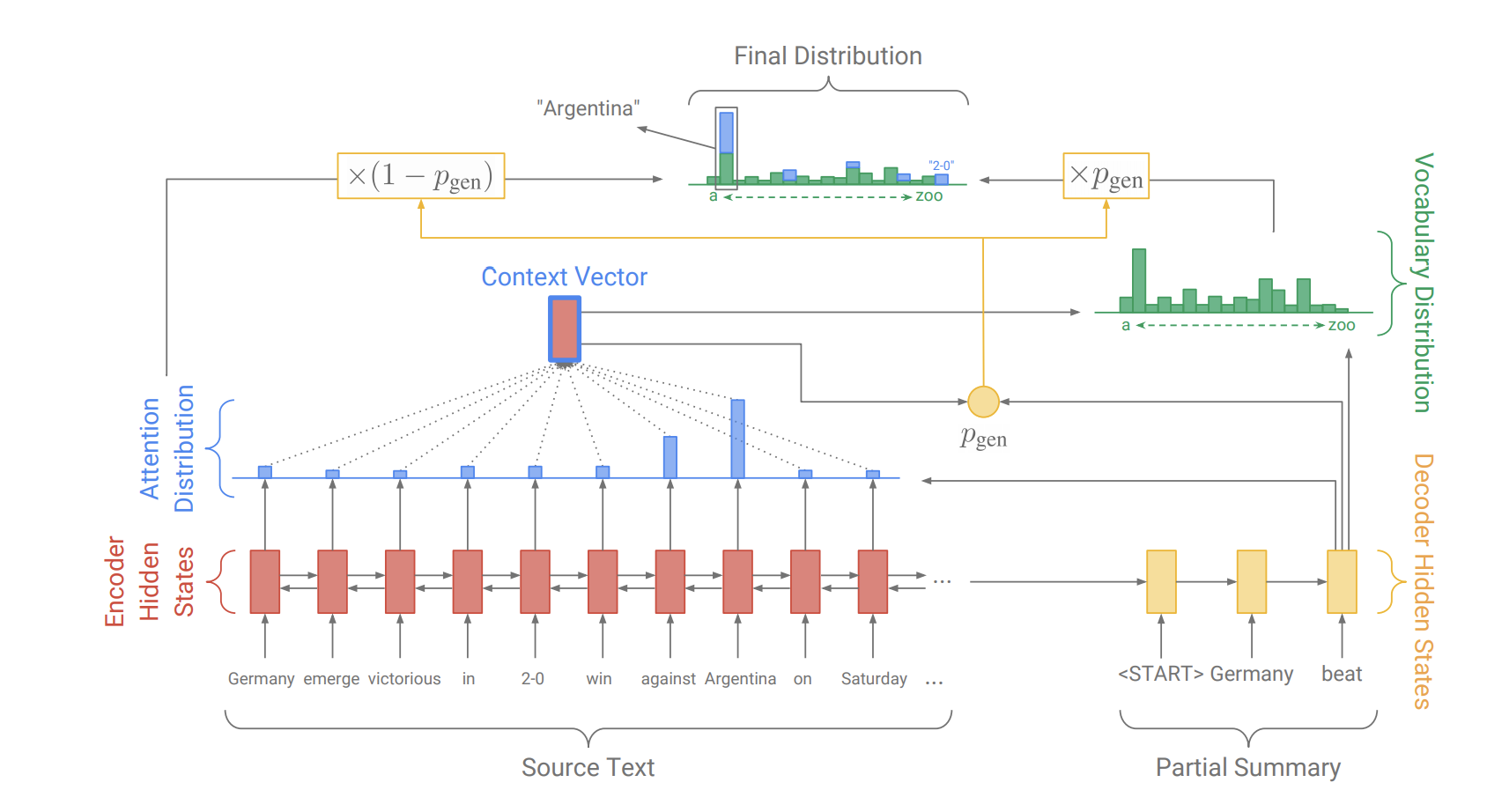
如何权衡一个词应该是生成的还是复制的?
原文中引入了一个权重$p_{gen}$ 。
从Baseline seq2seq的模型结构中得到了$st$和$h_t^*$,和解码器输入$x_t$一起来计算$p{gen}$:
这时,会扩充单词表形成一个更大的单词表—扩充单词表(将原文当中的单词也加入到其中),该时间步的预测词概率为:
其中 atiait 表示的是原文档中的词。我们可以看到解码器一个词的输出概率有其是否拷贝是否生成的概率和决定。当一个词不出现在常规的单词表上时$P{vocab}(w)$ 为0,当该词不出现在文档中$\sum{i:w_i=w} a_i^t$为0。
Coverage mechanism
原文的特色是运用了Coverage Mechanism来解决重复生成文本的问题,下图反映了前两个模型与添加了Coverage Mechanism生成摘要的结果:

蓝色的字体表示的是参考摘要,三个模型的生成摘要的结果差别挺大
红色字体表明了不准确的摘要细节生成(UNK未登录词,无法解决OOV问题);
绿色的字体表明了模型生成了重复文本。
为了解决此问题—Repitition,原文使用了在机器翻译中解决“过翻译”和“漏翻译”的机制—Coverage Mechanism。
具体实现上,就是将先前时间步的注意力权重加到一起得到所谓的覆盖向量 ct(coveragevector),用先前的注意力权重决策来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本。
指针生成网络(Pointer-Generator-Network)原理与实战
指针生成网络(Pointer-Generator-Network)原理与实战
Word Repetition
生成式任务存在文本重复问题解决方法—Coverage(每次预测都会的到概率分布,根据概率去强迫模型关注之前没有关注的内容)。

Text Summarization 在阿⾥
论文:Multi-Source Pointer Network for Product Title Summarization](https://arxiv.org/pdf/1808.06885.pdf))
商品标题摘要这个特殊问题天然存在对模型的两个限制:
1)摘要中不能引⼊不相关信息
2)摘要中必须保留源⽂本的关键信息(如品牌名和商品名)
Hyper-Parameter Tuning
Hand Turning
Good Coding Style
- 将各个参数的设置部分集中在⼀起。如果参数的设置分布在代码的各个地方,那么修改的过程想必会⾮常痛苦。
- 可以输出模型的损失函数值以及训练集和验证集上的准确率。
- 可以考虑设计⼀个⼦程序,可以根据给定的参数,启动训练并监控和周期性保存评估结果。再由⼀个主程序,分配参数以及并⾏启动⼀系列子程序。
General to Specific
- 建议先参考相关论⽂,以论⽂中给出的参数作为初始参数。⾄少论⽂中的参数,是个不差的结果。
- 如果找不到参考,那么只能⾃⼰尝试了。可以先从⽐较重要,对实验结果影响⽐较⼤的参数开始,同时固定其他参数,得到⼀个差不多的结果以后,在这个结果的基础上,再调其他参数。
例如学习率⼀般就⽐正则值,dropout值重要的话,学习率设置的不合适,不仅结果可能变差,模型甚⾄会⽆法收敛。 - 如果实在找不到⼀组参数让模型收敛。那么就需要检查,是不是其他地⽅出了问题,例如模型实现,数据等等。
Speed up Experiment
- 对训练数据进⾏采样。例如原来100W条数据,先采样成1W,进⾏实验看看。
- 减少训练类别。例如⼿写数字识别任务,原来是10个类别, 那么我们可以先在2个类别上训练,看看结果如何。
Experiment Number
learning rate: 1 0.1 0.01 0.001, ⼀般从1开始尝试。很少见learning rate⼤于10的。
学习率⼀般要随着训练进⾏衰减。
衰减系数⼀般是0.5。
衰减时机,可以是验证集准确率不再上升时,或固定训练多少个周期以后。
不过更建议使⽤⾃适应梯度的办法,例如adam,adadelta,rmsprop等,这些⼀般使⽤相关论⽂提供的默认值即可,可以避免再费劲调节学习率。
对RNN来说,有个经验,如果RNN要处理的序列⽐较长,或者RNN层数⽐较多,那么learning rate⼀般⼩⼀些⽐较好,否则有可能出现结果不收敛,甚⾄Nan等问题。⽹络层数: 先从1层开始。
- 每层结点数: 16 32 128,超过1000的情况⽐较少见。超过1W的从来没有见过。
- batch size: 128上下开始。batch size值增加,的确能提⾼训练速度。但是有可能收敛结果变差。如果显存⼤⼩允许,可以考虑从⼀个⽐较⼤的值开始尝试。因为batch size太⼤,⼀般不会对结果有太⼤的影响,⽽batch size太⼩的话,结果有可能很差。
- clip c(梯度裁剪): 限制最⼤梯度,其实是value = sqrt(w1^2+w2^2….),如果value超过了阈值,就算⼀个衰减系系数,让value的值等于阈值: 5,10,15
- dropout: 0.5
- L2正则:1.0,超过10的很少见。
- 词向量embedding⼤⼩:128,256
- 正负样本⽐例: 这个是⾮常忽视,但是在很多分类问题上,又⾮常重要的参数。很多⼈往往习惯使⽤训练数据中默认的正负类别⽐例,当训练数据⾮常不平衡的时候,模型很有可能会偏向数⽬较⼤的类别,从⽽影响最终训练结果。除了尝试训练数据默认的正负类别⽐例之外,建议对数⽬较⼩的样本做过采样,例如进⾏复制。提⾼他们的⽐例,看看效果如何,这个对多分类问题同样适⽤。在使⽤mini-batch⽅法进⾏训练的时候,尽量让⼀个batch内,各类别的⽐例平衡,这个在图像识别等多分类任务上⾮常重要。
HP Range
建议优先在对数尺度上进⾏超参数搜索。⽐较典型的是学习率和正则化项,我们可以从诸如0.001 0.01 0.1 1 10,以10为阶数进⾏尝试。
因为他们对训练的影响是相乘的效果。不过有些参数,还是建议在原始尺度上进⾏搜索,例如dropout值: 0.3 0.5 0.7)。
Auto Turning
Tensorboard(Keras Turner)

