Text Summarization - NLG
Natural Language Generation
NLG Introduction
1、Application
Translation
Document Summarization
E-mail Summarization
Meeting Summarization
2、What’s Natural Language Generation?
Any task involving text production for human consumption requires natural language generation
NLG 是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
3、自然语言生成的2种方式:
text – to – text:文本到语言的生成
data – to – text :数据到语言的生成
4、NLG的3个LEVEL
1、简单的数据合并:自然语言处理的简化形式,这将允许将数据转换为文本(通过类似Excel的函数)。为了关联,以邮件合并(MS Word mailmerge)为例,其中间隙填充了一些数据,这些数据是从另一个源(例如MS Excel中的表格)中检索的。
2、模板化的 NLG :这种形式的NLG使用模板驱动模式来显示输出。以足球比赛得分板为例。数据动态地保持更改,并由预定义的业务规则集(如if / else循环语句)生成。
3、高级 NLG :这种形式的自然语言生成就像人类一样。它理解意图,添加智能,考虑上下文,并将结果呈现在用户可以轻松阅读和理解的富有洞察力的叙述中。
5、NLG 的6个步骤
第一步:内容确定 – Content Determination
作为第一步,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 – Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达“什么时间”“什么地点”“哪2支球队”,然后再表达“比赛的概况”,最后表达“比赛的结局”。
第三步:句子聚合 – Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 – Lexicalisation
当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 – Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于“REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 – Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
6、NLG 的3种典型应用
NLG 的不管如何应用,大部分都是下面的3种目的:
- 能够大规模的产生个性化内容
- 帮助人类洞察数据,让数据更容易理解
- 加速内容生产
NLG Decoding Strategy
1、Greedy Decoding
Greedy Decoding(贪心算法):挑选P中概率最高的一个作为预测结果,停止条件是遇到\
1.1 Greedy Search
核心思想:每一步取当前最可能的结果,作为最终结果。
On each step of decoder, keep track of the k most probable partial translations (which we call hypotheses)。
在解码器的每一步,跟踪k个最可能的部分翻译(我们称之为假设)。
具体方法:获得新生成的词是vocab中各个词的概率,取argmax作为需要生成的词向量索引,继而生成后一个词。
1.2 Beam Search
对比贪心算法,beam search取到了概率中最大的K个值进行下一步的运算,每一步都取到概率中的Top-k。Beam Search也有一些限制条件:
1、timestep T(预定义值需要自己根据应用场景来设定)
2、生成假设(hypothese)的数量是需要考虑的。K的数值代表beam size,beam size设置的大小也有很多的影响,具体表现为:
beam size过小时会出现生成的语句没有语法性、不自然、不顺畅、不正确等问题;
beam size变大时上面的问题会缓解,但是也存在一些缺点:
1、k变大,相应的计算代价也会变大,
2、Blue score指标会下降的非常快,
3、生成的句子变短了,
4、topic相关度会下降。
核心思想:beam search尝试在广度优先基础上进行进行搜索空间的优化(类似于剪枝)达到减少内存消耗的目的。
具体方法:在decoding的每个步骤,我们都保留着 top K 个可能的候选单词,然后到了下一个步骤的时候,我们对这 K 个单词都做下一步 decoding,分别选出 top K,然后对这 $K^2$ 个候选句子再挑选出 top K 个句子。以此类推一直到 decoding 结束为止。当然 Beam Search 本质上也是一个 greedy decoding 的方法,所以我们无法保证自己一定可以得到最好的 decoding 结果。
1.3 Greedy Decoding与Beam Search存在问题
①容易出现很无聊的回答:I don’t know.
②容易重复自己:I don’t know. I don’t know. I don’t know. I don’t know. I don’t know. I don’t know.
1.4 NLG中重复性问题
出现重复性原因是重复的语句会降低模型的loss,也就是说模型可以从重复的语句中学到东西。
解决方法:
1、将前面生成的文本写入到n-gram中,
2、在loss中加入多项式惩罚相似文本,
3、对loss进行改变,
4、F2 softmax,将频率分类,再和原loss相乘。
2、Sampling引入随机性
核心思想: 根据单词的概率分布随机采样
2.1 随机Sampling(vocab($y_i$))
我们可以在生成文本的时候引入一些随机性。例如现在语言模型告诉我们下一个单词在整个单词表上的概率分布是,那么我们就可以按照这个概率分布进行随机采样,然后决定下一个单词生成什么。采样相对于greedy方法的好处是,我们生成的文字开始有了一些随机性,不会总是生成很机械的回复了。
2.2 随机Sampling存在问题
①生成的话容易不连贯,上下文比较矛盾。
②容易生成奇怪的话,出现罕见词。
2.3 top-k sampling
可以缓解生成罕见单词的问题。比如说,我们可以每次只在概率最高的50个单词中按照概率分布做采样。
我只保留top-k个probability的单词,然后在这些单词中根据概率做sampling。
2.4 Neucleus Sampling
Neucleus Sampling的基本思想是,top p sampling,例如设置一个threshold,p=0.95。
3、Sampling Strategy
常用的随机采样会随机选取到文本出现概率很低的词语,这样对结果很不利,所以会有一些采样的策略来解决这些问题。
方法:
1、Temperature Sampling
通过选取temperature大小,来将重要词的概率变大,将不重要词的概率变小,突出重要部分。
2、Top-K Sampling
根据不同场景选取不同top-k个样本,存在问题:会把距离top近的其他样本舍弃掉。
3、Top-p(p代表percentage)
本质上Top-p sampling和Top-k sampling都是从truncated vocabulary distribution中sample token,区别在于置信区间的选择不同。
NLG的评估指标
1、Rouge-N(N代表n-gram)
2、Rouge-L(L代表the longest common subseqence 最长子序列)
3、Rouge-s(s代表skip-gram)
这几种评价指标前两种用的较多,需要重点掌握。
现在自然语言生成Structure
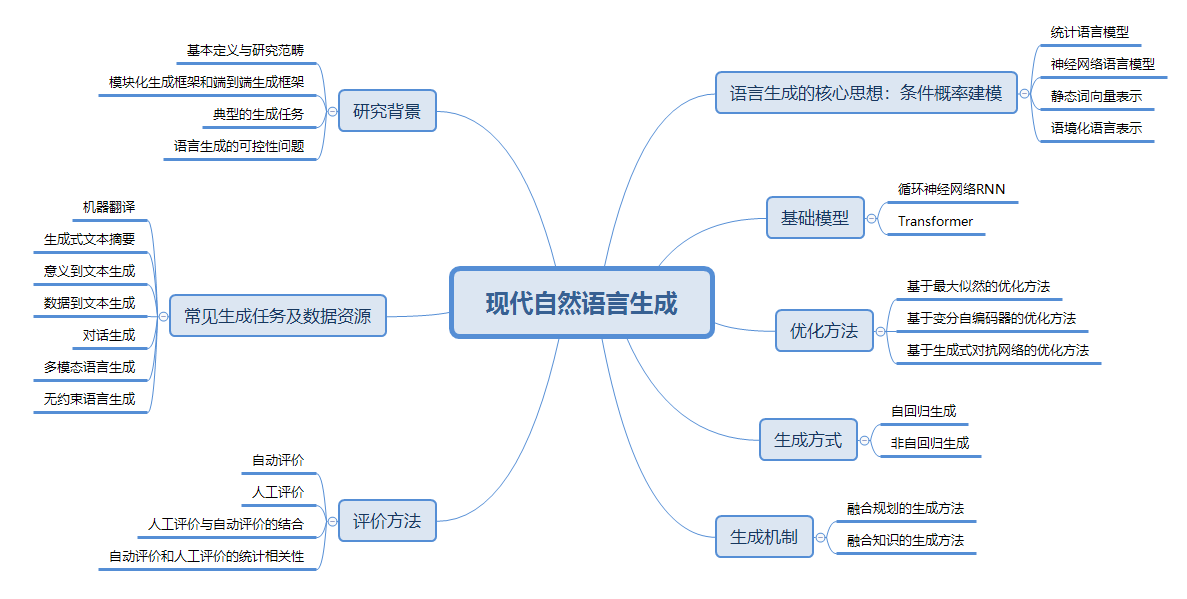
1、CTC loss的几种解码方法:贪心搜索 (greedy search)、束搜索(Beam Search)、前缀束搜索(Prefix Beam Search)
3、Pretraining-Based Natural Language Generation for Text Summarization
4、自然语言简报

