Text Summarization
Definitions
Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning.
自动文本摘要是生成简洁流畅的摘要,同时保留关键信息内容和整体含义的任务
categories
Extractive Summarization
抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要
Abstractive Summarization
生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于生成式自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。
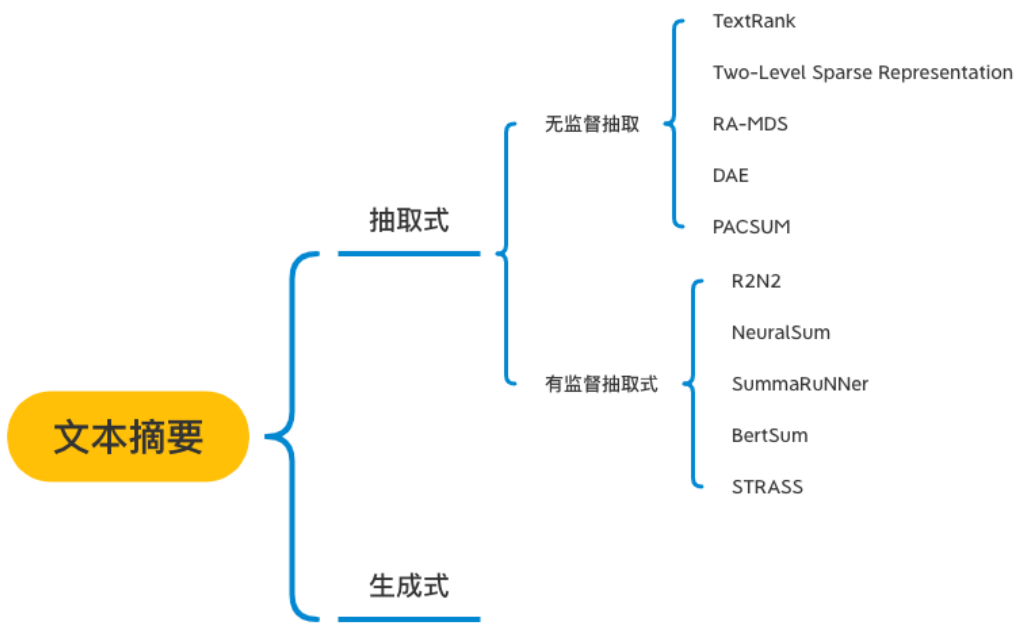
目前主要方法有:
基于统计:统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
基于图模型:构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
基于潜在语义:使用主题模型,挖掘词句隐藏信息。例如,采用LDA,HMM
基于整数规划:将文摘问题转为整数线性规划,求全局最优解。
Text Rank
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法,通过把文本分割成若干组成单元(单词、句子)并建立图模型,利用投票机制对文本中的重要成分进行排序,仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、M 等模型不同,TextRank不需要事先对多篇文档进行学习训练,因其简洁有效而得到广泛应用。
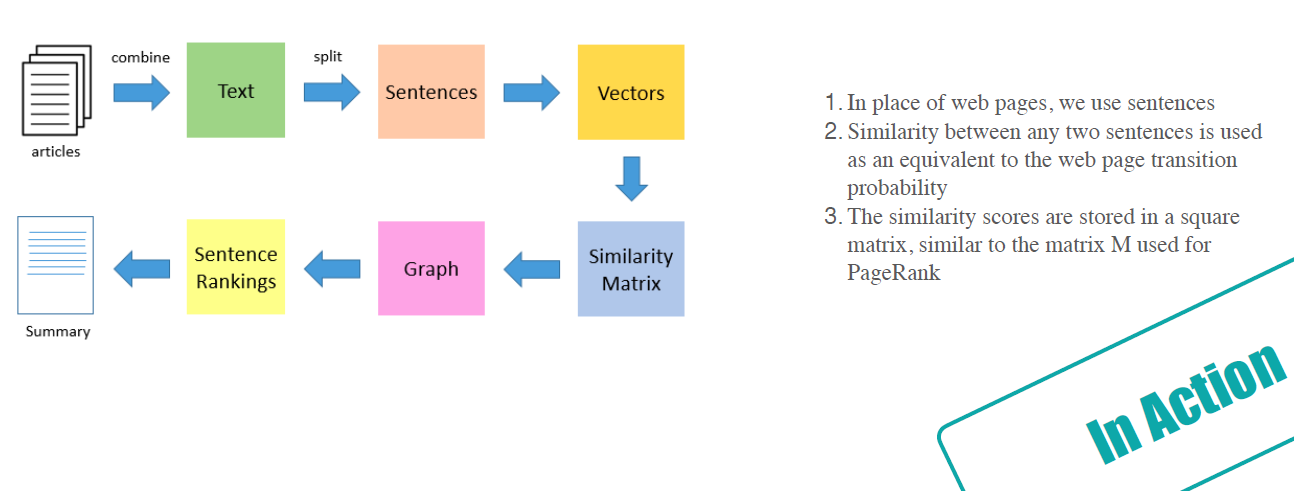
1. 第一步是把所有文章整合成文本数据
2. 接下来把文本分割成单个句子
3. 然后,我们将为每个句子找到向量表示(词向量)。
4. 计算句子向量间的相似性并存放在矩阵中
5. 然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算。
6. 最后,一定数量的排名最高的句子构成最后的摘要。
TFIDF&TextRank对比总结
TextRank与TFIDF均严重依赖于分词结果——如果某词在分词时被切分成了两个词,那么在做关键词提取时无法将两个词黏合在一起(TextRank有部分黏合效果,但需要这两个词均为关键词)。因此是否添加标注关键词进自定义词典,将会造成准确率、召回率大相径庭。
TextRank的效果并不优于TFIDF。
TextRank虽然考虑到了词之间的关系,但是仍然倾向于将频繁词作为关键词。
此外,由于TextRank涉及到构建词图及迭代计算,所以提取速度较慢。
发现以上两种方法本质上还是基于词频,这也导致了我们在进行自然语言处理的时候造成的弊端,因为我们阅读一篇文章的时候,并不是意味着主题词会一直出现,特别对于中文来说,蕴含的中心思想也往往不是一两个词能够说明的,这也是未来自然语言方面要解决的基于语义的分析,路还很长。
Recurrent Neural Network (RNN)
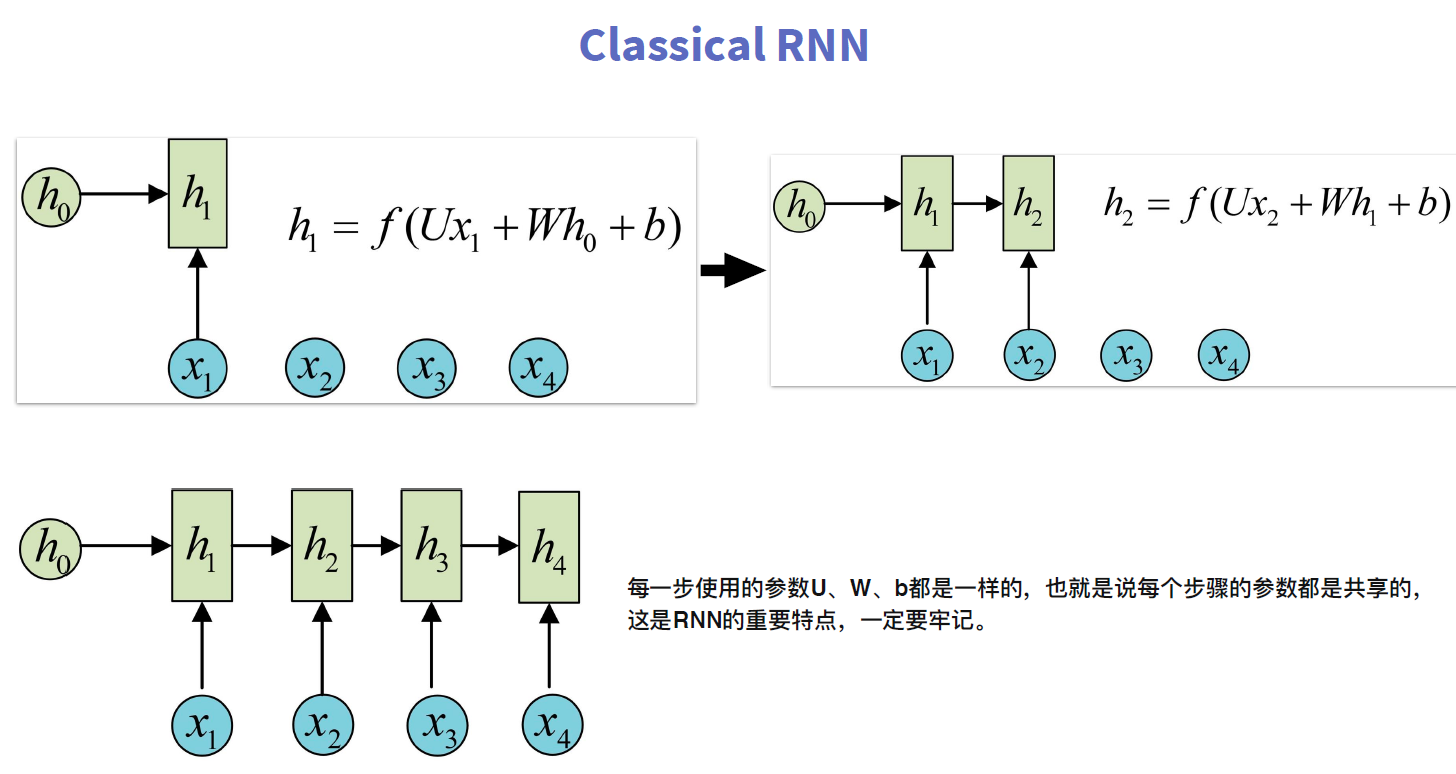
RNN 跟传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。如下图所示:
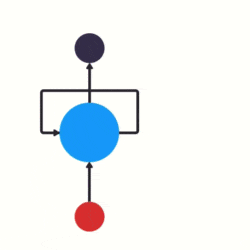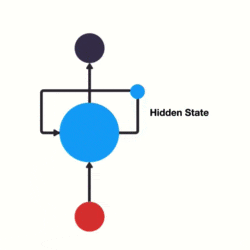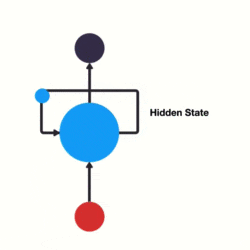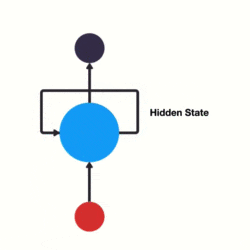
假如需要判断用户的说话意图(问天气、问时间、设置闹钟…),用户说了一句“what time is it?”我们需要先对这句话进行分词:
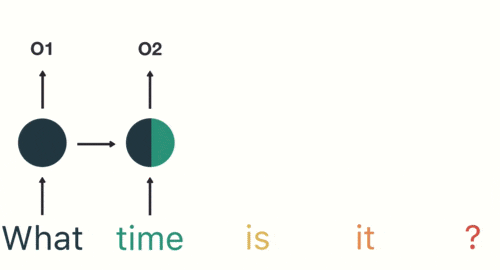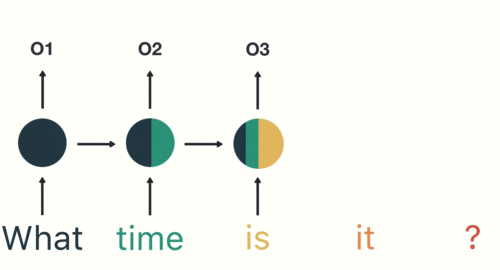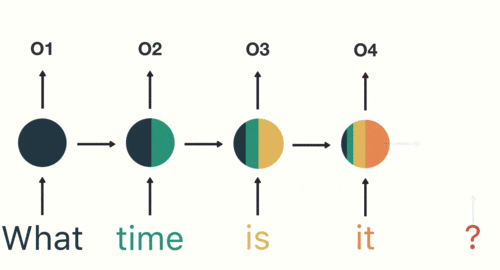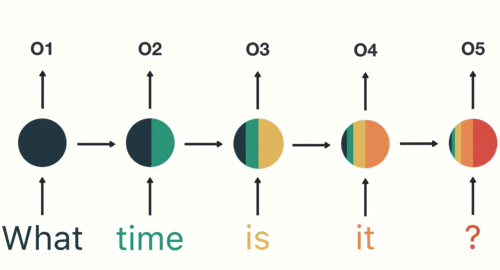
当我们判断意图的时候,只需要最后一层的输出「05」,如下图所示:
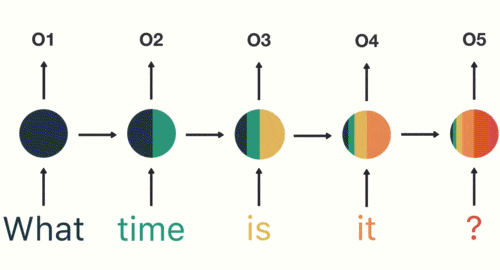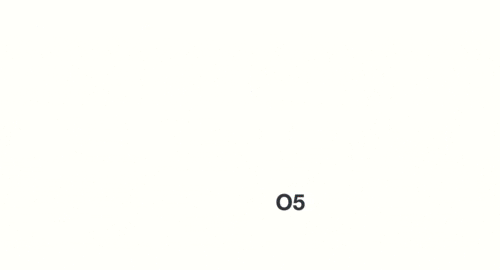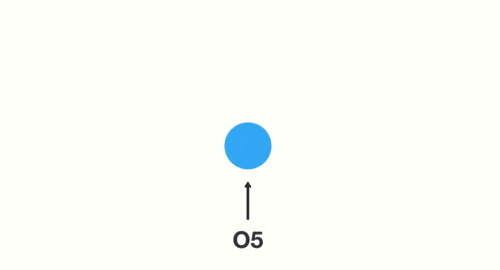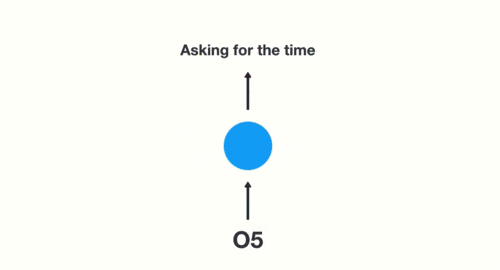
Solve Vanishing Gradient

RNN优点
1、The main advantage of RNN over ANN is that RNN can model sequence of data (i.e. time series) so that each sample can be assumed to be dependent on previous ones
2、Share Parameters
RNN 的缺点也比较明显
通过上面的例子,我们已经发现,短期的记忆影响较大(如橙色区域),但是长期的记忆影响就很小(如黑色和绿色区域),这就是 RNN 存在的短期记忆问题。
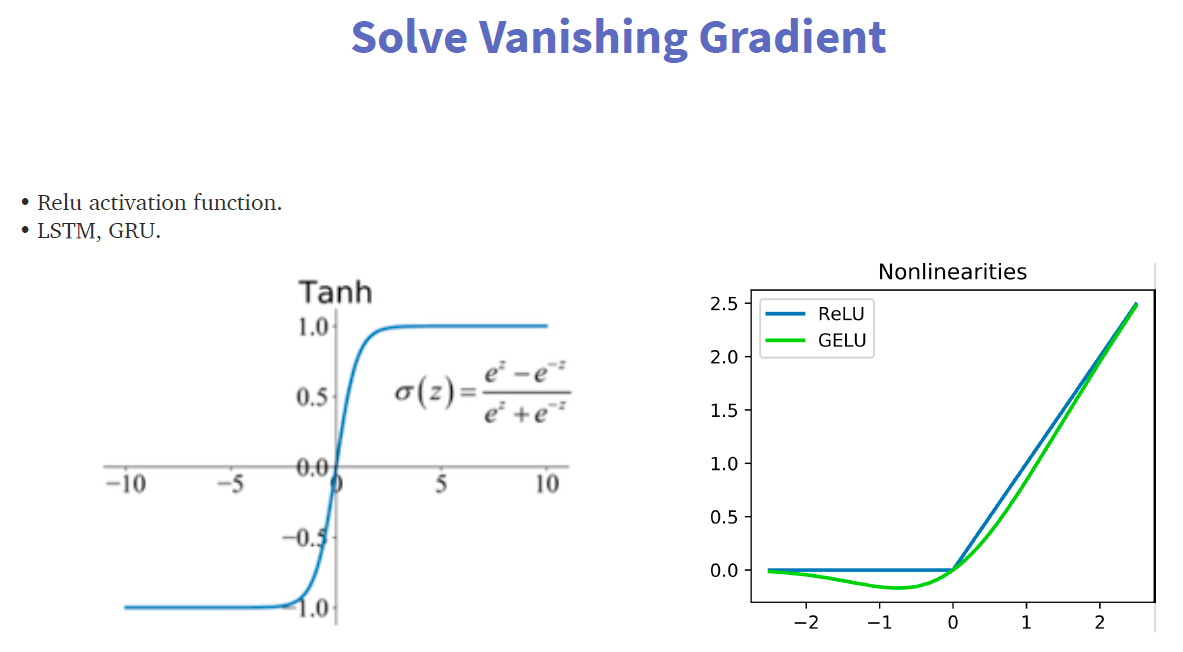
1、 Gradient vanishing and exploding problems
2、Training an RNN is a very difficult task
3、It cannot process very long sequences if using tanh or relu as an activation function
4、RNN 有短期记忆问题,无法处理很长的输入序列
5、训练 RNN 需要投入极大的成本
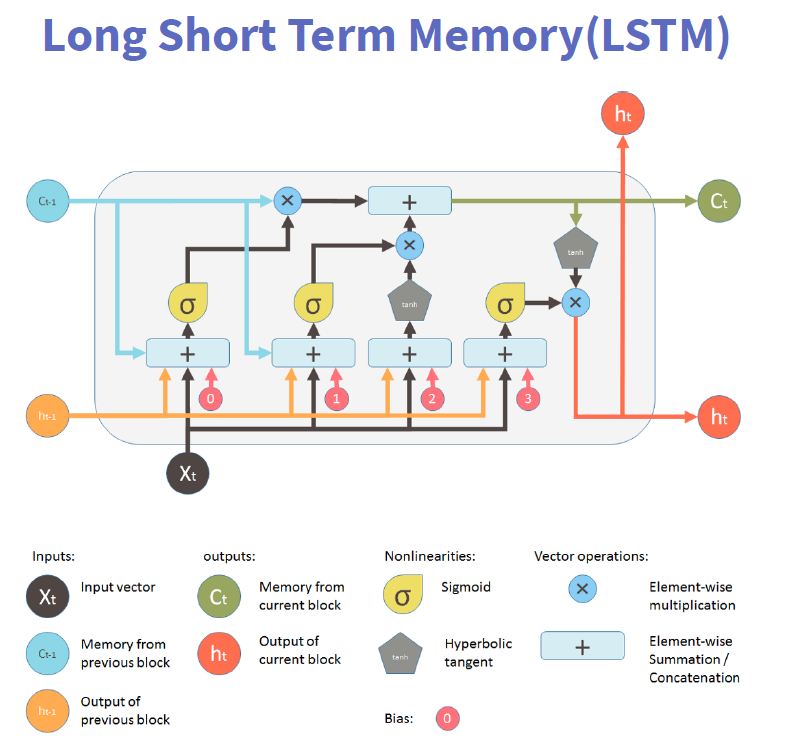
Long Short Term Memory (LSTM)
RNN 是一种死板的逻辑,越晚的输入影响越大,越早的输入影响越小,且无法改变这个逻辑。
LSTM 做的最大的改变就是打破了这个死板的逻辑,而改用了一套灵活了逻辑——只保留重要的信息。
简单说就是:抓重点!
GRU
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢。
下图1-1引用论文中的一段话来说明GRU的优势所在。

简单译文:我们在我们的实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
简单来说就是贫穷限制了我们的计算能力…
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。
与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。
Differences & Trade-off
1、对于 LSTM 与 GRU ⽽⾔, 由于 GRU 参数更少,收敛速度更快,因此其实际花费时间要少很多,这可以⼤⼤加速了我们的迭代过程。
2、⽽从表现上讲,⼆者之间孰优孰劣并没有定论,这要依据具体的任务和数据集⽽定,⽽实际上,⼆者之间的 performance 差距往往并不⼤,远没有调参所带来的效果明显,与其争论 LSTM 与 GRU 孰优孰劣, 不如在 LSTM 或 GRU的激活函数(如将tanh改为tanh变体)和权重初始化上功夫。
3、⼀般来说,我会选择GRU作为基本的单元,因为它收敛速度快,可以加速试验进程,快速迭代,⽽我认为快速迭代这⼀特点很重要。如果实现没其余优化技,才会尝试将 GRU 换为 LSTM,看看有没有什么惊喜发⽣。
Seq2seq Architecture
什么是 Encoder-Decoder
Encoder-Decoder 模型主要是 NLP 领域里的概念。它并不特值某种具体的算法,而是一类算法的统称。Encoder-Decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
Encoder-Decoder 这个框架很好的诠释了机器学习的核心思路:将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题。
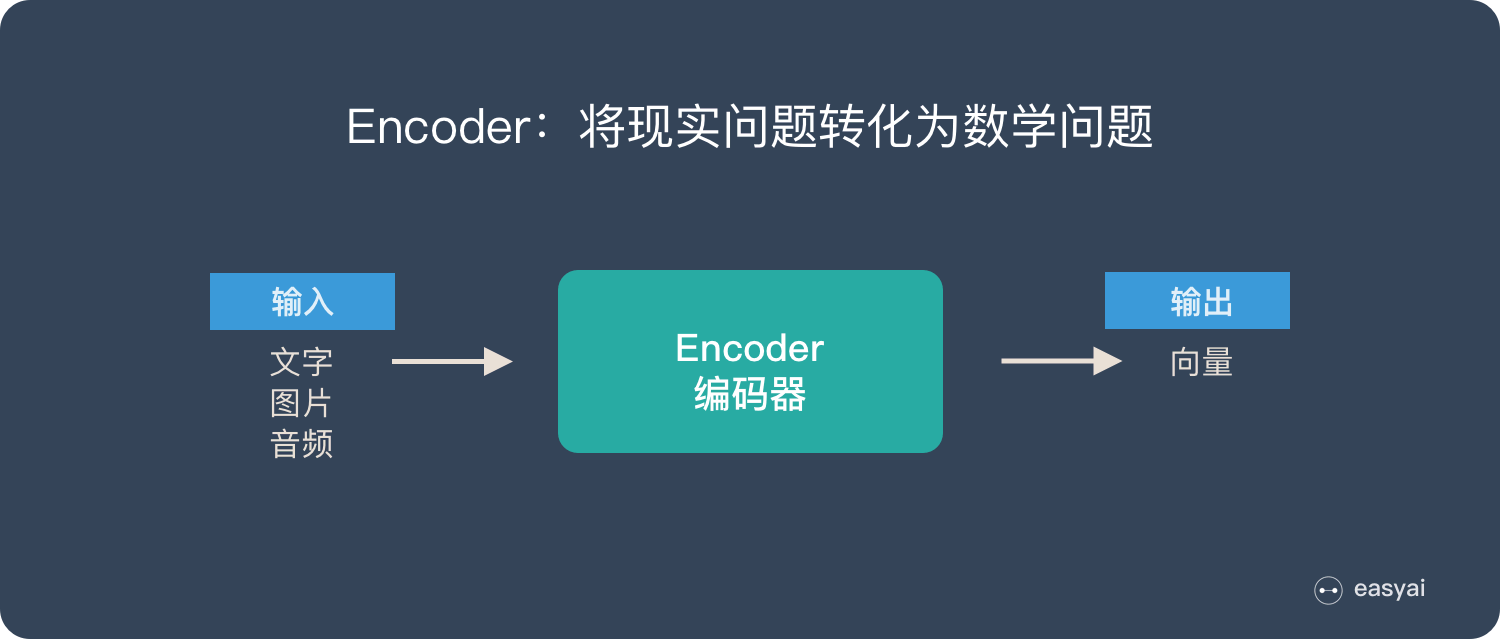
Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」
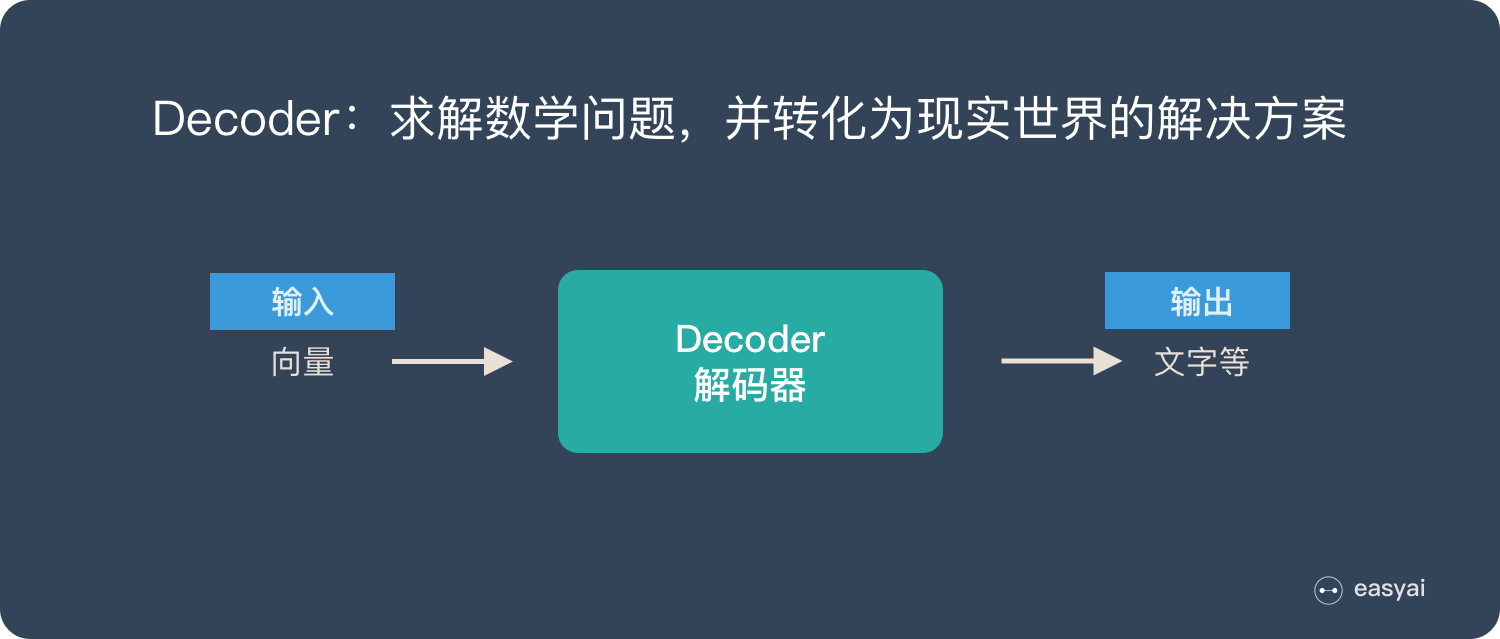
Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」
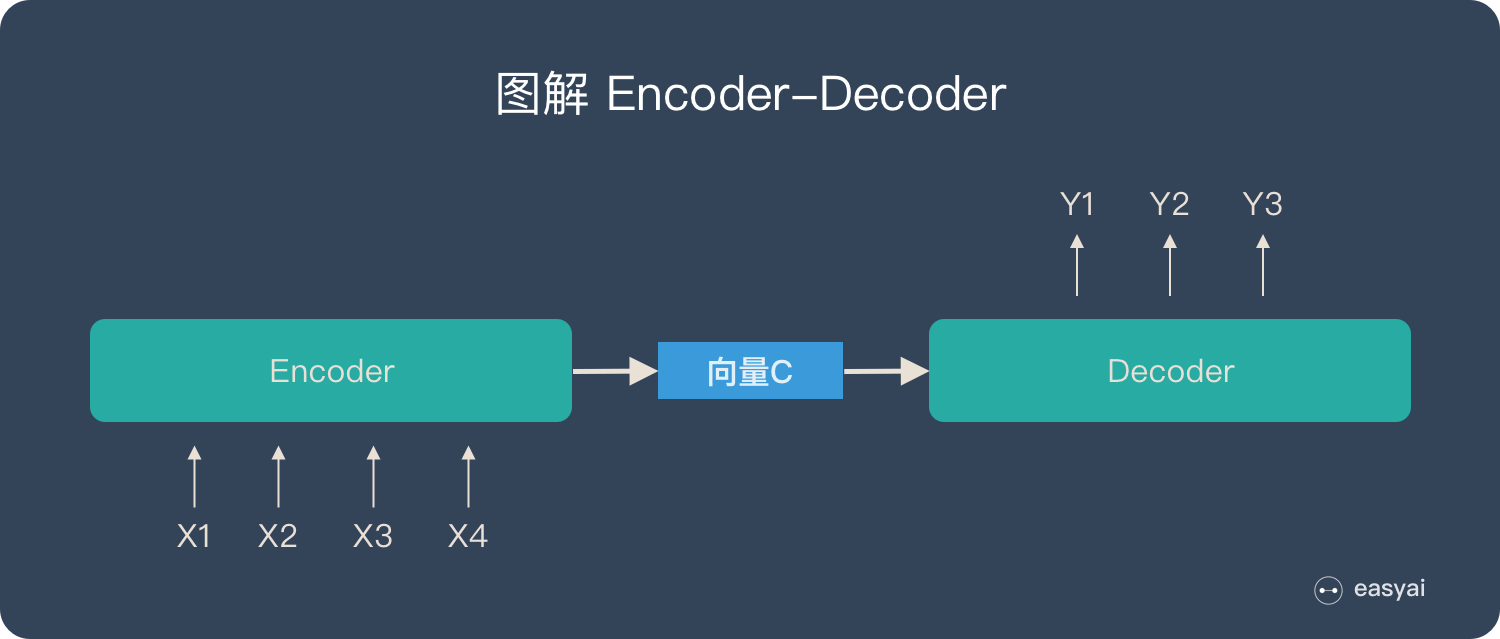
把 2 个环节连接起来,用通用的图来表达则是下面的样子:
关于 Encoder-Decoder,有2 点需要说明:
- 不论输入和输出的长度是什么,中间的「向量 c」 长度都是固定的(这也是它的缺陷,下文会详细说明)
- 根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN ,但通常是其变种 LSTM 或者 GRU )
只要是符合上面的框架,都可以统称为 Encoder-Decoder 模型。
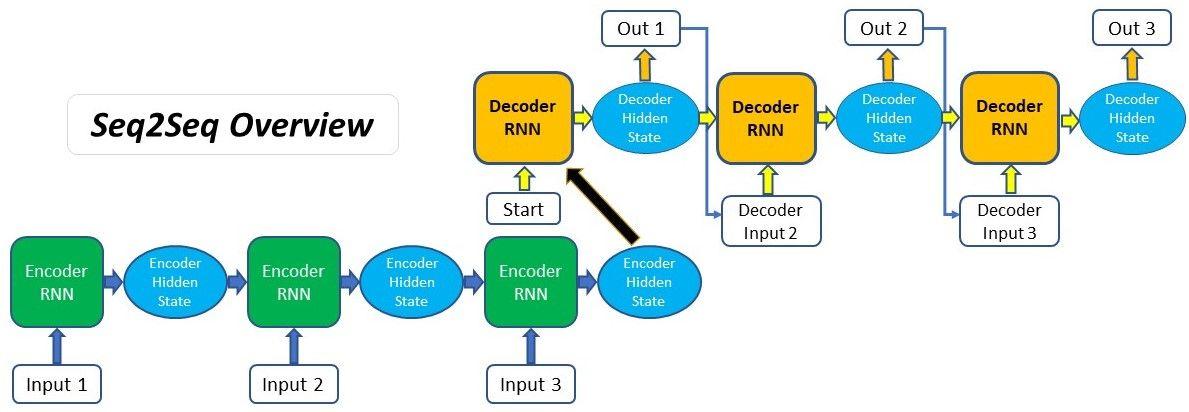
什么是 Seq2Seq
Seq2Seq(是 Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。例如下图:
如上图:输入了 6 个汉字,输出了 3 个英文单词。输入和输出的长度不同。
Seq2Seq 的由来
在 Seq2Seq 框架提出之前,深度神经网络在图像分类等问题上取得了非常好的效果。在其擅长解决的问题中,输入和输出通常都可以表示为固定长度的向量,如果长度稍有变化,会使用补零等操作。
然而许多重要的问题,例如机器翻译、语音识别、自动对话等,表示成序列后,其长度事先并不知道。因此如何突破先前深度神经网络的局限,使其可以适应这些场景,成为了13年以来的研究热点,Seq2Seq框架应运而生。
「Seq2Seq」和「Encoder-Decoder」的关系
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
而 Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型(强调方法)的范畴。
总结一下的话:
- Seq2Seq 属于 Encoder-Decoder 的大范畴
- Seq2Seq 更强调目的,Encoder-Decoder 更强调方法
Encoder-Decoder 的缺陷
上文提到:Encoder(编码器)和 Decoder(解码器)之间只有一个「向量 c」来传递信息,且 c 的长度固定。
为了便于理解,我们类比为「压缩-解压」的过程:
将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。再将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。
Encoder-Decoder 就是类似的问题:当输入信息太长时,会丢失掉一些信息。
Attention Mechanism
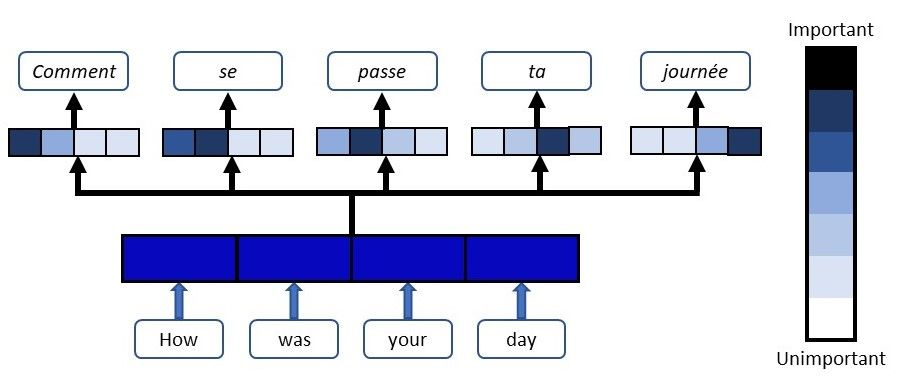
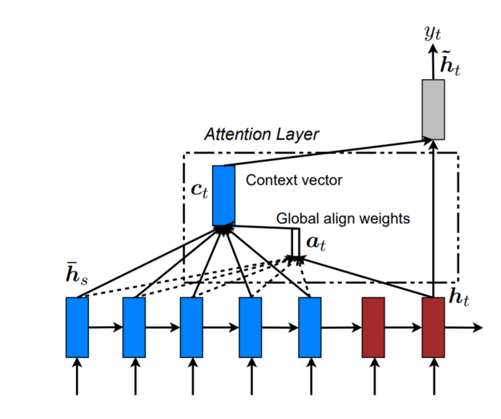
Attention 机制就是为了解决「信息过长,信息丢失」的问题。
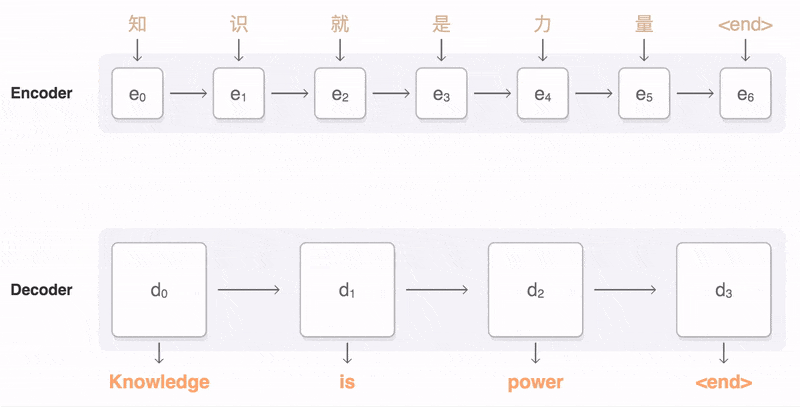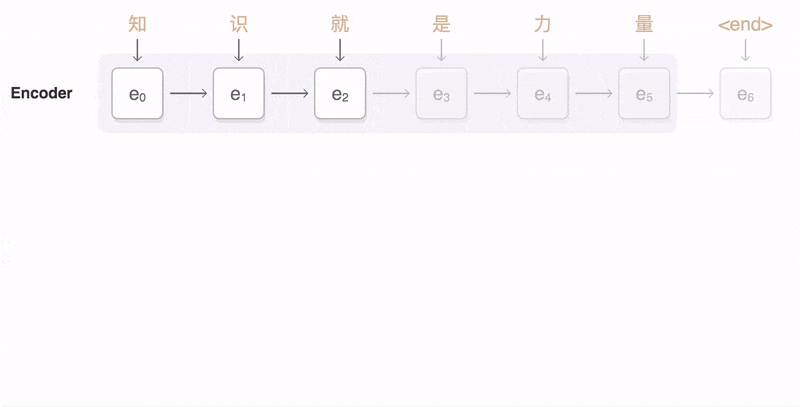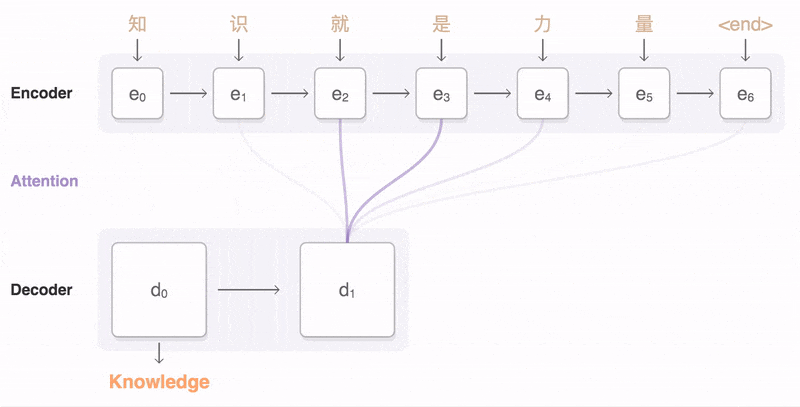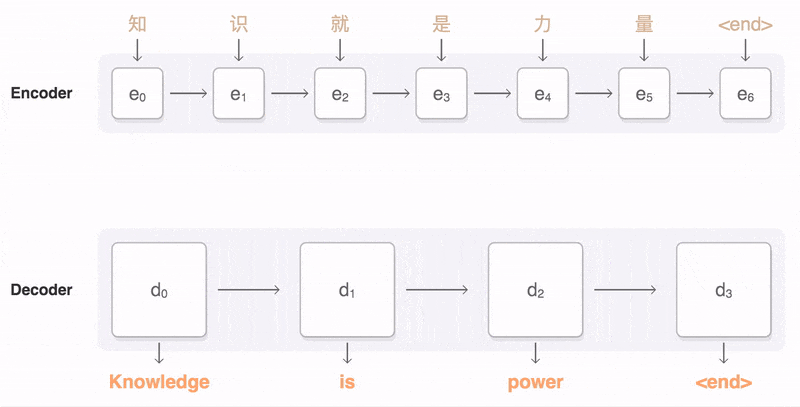
Attention 模型的特点是 Eecoder 不再将整个输入序列编码为固定长度的「中间向量 C」 ,而是编码成一个向量的序列。引入了 Attention 的 Encoder-Decoder 模型如下图:
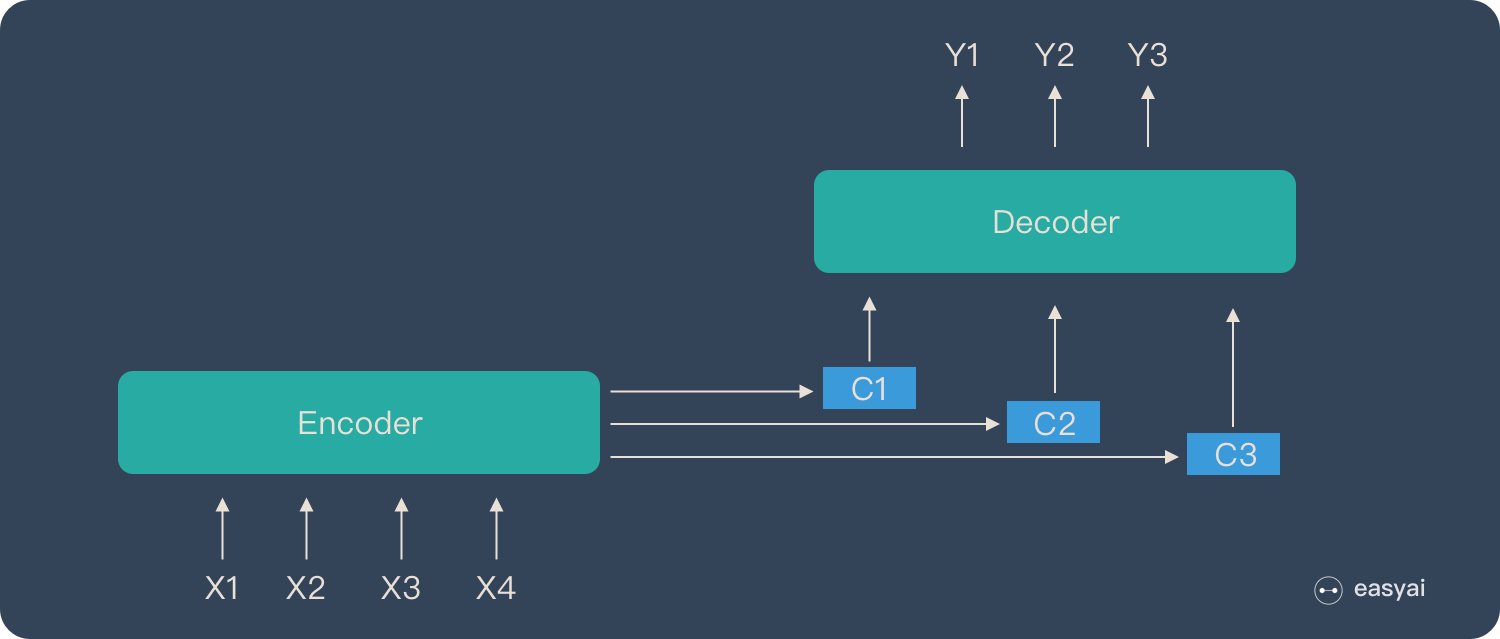
这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
Attention 是一个很重要的知识点,想要详细了解 Attention,请查看《一文看懂 Attention(本质原理+3大优点+5大类型)》
Additive Attention (Bahdanau Attention)
传统seq2seq模型中encoder将输入序列编码成一个context向量,decoder将context向量作为初始隐状态,生成目标序列。随着输入序列长度的增加,编码器难以将所有输入信息编码为单一context向量,编码信息缺失,难以完成高质量的解码。
注意力机制是在每个时刻解码时,基于当前时刻解码器的隐状态、输入或输出等信息,计算其对输入序列各位置隐状态的注意力(分数)并加权生成context向量用于当前时刻解码。引入注意力机制,使得不同时刻的解码能够关注不同位置的输入信息,提高预测准确性。
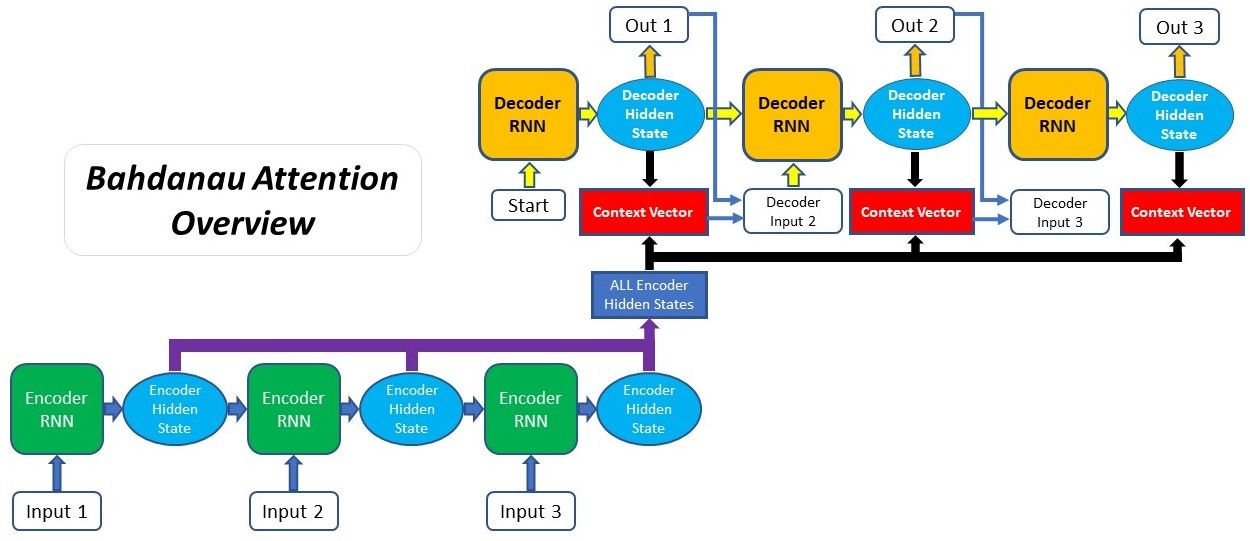
Bahdanau Attention Mechanism
Bahdanau本质是一种 加性attention机制,将decoder的隐状态和encoder所有位置输出通过线性组合对齐,得到context向量,用于改善序列到序列的翻译模型。
本质:两层全连接网络,隐藏层激活函数tanh,输出层维度为1。
Bahdanau的特点为:
1、编码器隐状态 :编码器对于每一个输入向量产生一个隐状态向量;
2、计算对齐分数:使用上一时刻的隐状态$s_{t-1}$ 和编码器每个位置输出$s_t$计算对齐分数(使用前馈神经网络计算),编码器最终时刻隐状态可作为解码器初始时刻隐状态;
3、概率化对齐分数:解码器上一时刻隐状态$s_{t-1}$在编码器每个位置输出的对齐分数,通过softmax转化为概率分布向量;
4、计算上下文向量:根据概率分布化的对齐分数,加权编码器各位置输出,得上下文向量$c_t$;
5、解码器输出:将上下文向量$ct$和上一时刻编码器输出$\hat y{t-1} $对应的embedding拼接,作为当前时刻编码器输入,经RNN网络产生新的输出和隐状态,训练过程中有真实目标序列$y=(y1···y_m)$,多使用$y{t-1}$取代$\hat y_{t-1} $作为解码器t时刻输入;
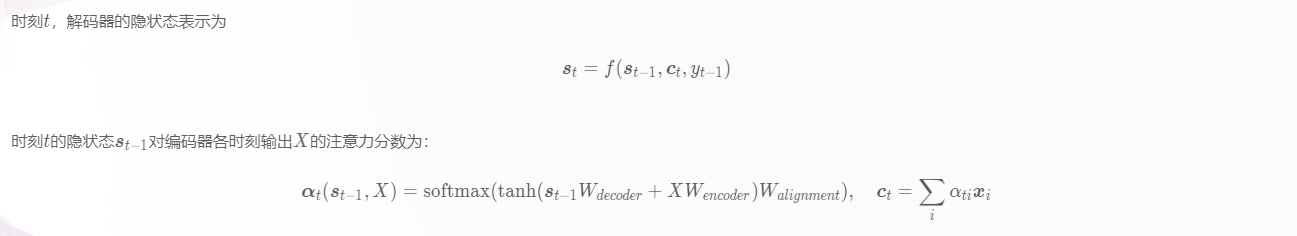
使用Bahdanau注意力机制的解码过程:
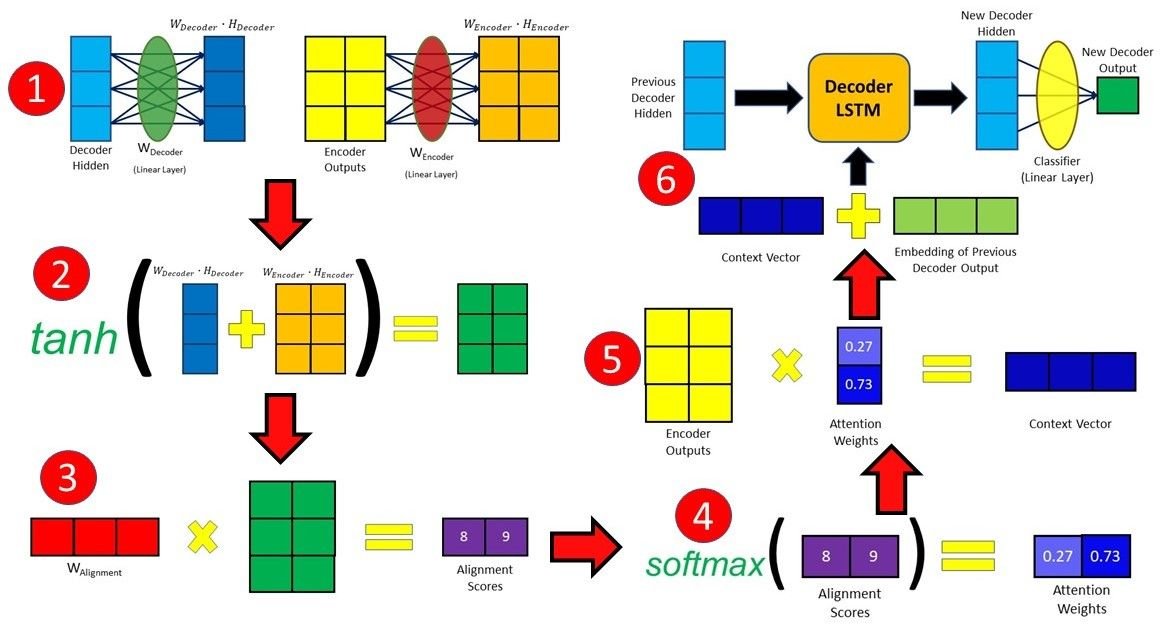
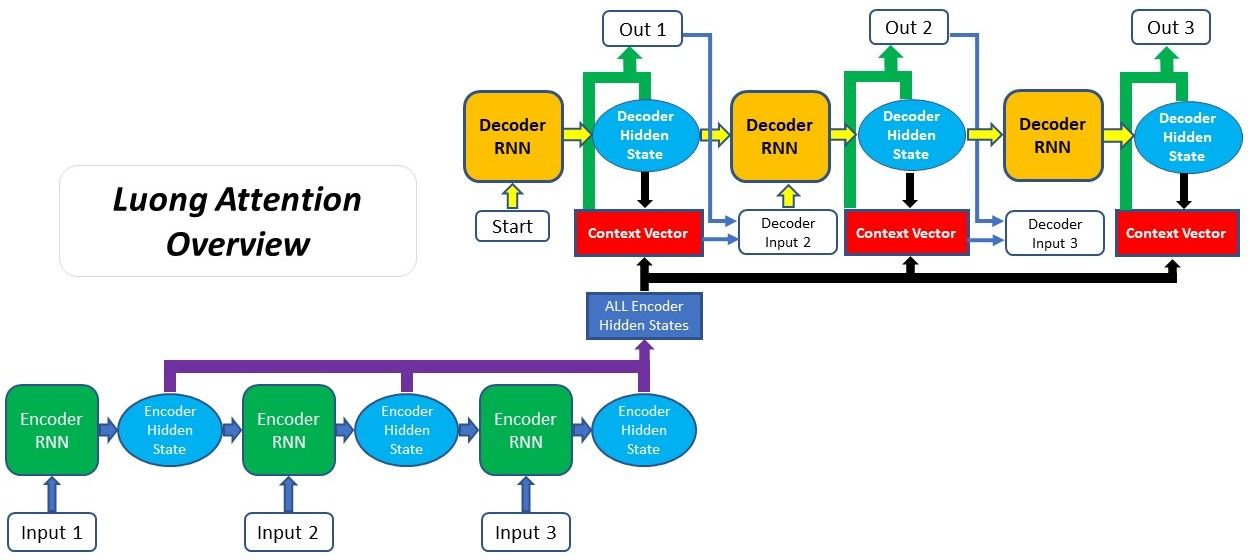
Multiplicative Attention (Luong Attention)
Luong本质是一种 乘性attention机制,将解码器隐状态和编码器输出进行矩阵乘法,得到上下文向量。
Luong注意力机制是对Bahdanau注意力机制的改进,根据是否全部使用所有编码器输出分为两种:全局注意力和局部注意力,全局注意力适合用于短输入序列,局部注意力适合用于长输入序列(计算全局注意力代价高),以下内容仅介绍全局注意力。
Luong注意力机制与Bahdanau注意力机制的主要不同点:
1、对齐分数计算:使用当前时刻的隐状态$s_t$计算在编码器位置i输出的对齐分数;
2、解码器输出:解码器在t时刻,拼接上下文向量$ct$ 和当前时刻隐状态$s_t$,经全连接层,产生当前时刻输出$\hat y{t+1}$ ,并作为下一时刻输入;
3、流程图当前时刻计算的context向量,会被应用到下一时刻的输入;
Luong注意力的三种计算方法:

Teacher Forcing
Teacher Forcing是一种用来训练循环神经网络模型的方法,这种方法以上一时刻的输出作为下一时刻的输入。
Layer & Model in Action
Tensorflow 2 API (https://github.com/lyhue1991/eat_tensorflow2_in_30_days)
Tensorflow的一些配置
设置Tensorflow使用的显存大小
获得当前主机上特定运算设备的列表
1 | gpus = tf.config.experimental.list_physical_devices(device_type='GPU') |
设置当前程序可见的设备范围
默认情况下 TensorFlow 会使用其所能够使用的所有 GPU。
1 | tf.config.experimental.set_visible_devices(devices=gpus[2:4], device_type='GPU') |
设置之后,当前程序只会使用自己可见的设备,不可见的设备不会被当前程序使用。
另一种方式是使用环境变量 CUDA_VISIBLE_DEVICES 也可以控制程序所使用的 GPU。
在终端输入
1 | export CUDA_VISIBLE_DEVICES=2,3 |
或者在代码里加入
1 | import os |
都可以达到同样的效果。
显存的使用
默认情况下,TensorFlow 将使用几乎所有可用的显存,以避免内存碎片化所带来的性能损失。
但是TensorFlow 提供两种显存使用策略,让我们能够更灵活地控制程序的显存使用方式:
仅在需要时申请显存空间【按需设置显存】(程序初始运行时消耗很少的显存,随着程序的运行而动态申请显存);
限制消耗固定大小的显存【定量设置显存】(程序不会超出限定的显存大小,若超出的报错)。
设置仅在需要时申请显存空间。
1 | for gpu in gpus: |
下面的方式是设置Tensorflow固定消耗GPU:0的2GB显存。
1 | tf.config.experimental.set_virtual_device_configuration( |
单GPU模拟多GPU环境
上面的方式不仅可以设置显存的使用,还可以在只有单GPU的环境模拟多GPU进行调试。
1 | tf.config.experimental.set_virtual_device_configuration( |
上面的代码就在GPU:0上建立了两个显存均为 2GB 的虚拟 GPU。
Tensorflow 错误
Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
解决方案:
1 | import tensorflow as tf |
总结
1、关于seq2seq的整个流程,可以参考https://www.toutiao.com/i6648878247188627972/。
2、关于loss函数中的trick,对于Seq2Seq模型来说,输入和输出序列的class便是词汇表的大小,而对于训练集来说,输入和输出的词汇表的大小是比较大的。为了减少计算每个词的softmax的时候的资源压力,通常会减少词汇表的大小,但是便会带来另外一个问题,由于词汇表的词量的减少,语句的Embeding的id表示时容易大频率的出现未登录词‘UNK’。所以计算词汇表的softmax的时候,并不采用全部的词汇表中的词,而是进行一定手段的sampled的采样,从而近似的表示词汇表的loss输出,sampled采样需要定义好候选分布Q。即按照什么分布去采样。因此loss函数可以用sampled_softmax_loss。
3、在训练过程中通常采用的是teacher-forcing进行训练纠正,但是在预测阶段,是不知道真实标签的,所以会引起Exposure Bias, 使用Beam Search的Encoder的方式也能一定程度上降低Exposure Bias问题。
4、关于oov问题和低频词。OOV表示的是词汇表外的未登录词,低频词则是词汇表中的出现次数较低的词。在Decoder阶段时预测的词来自于词汇表,这就造成了未登录词难以生成,低频词也比较小的概率被预测生成。PGN网络可以解决(之后的课程会有)。
参考
TextRank算法原理与提取关键词、自动提取摘要PYTHON
Attention机制(Bahdanau attention & Luong Attention)
Attention: Sequence 2 Sequence model with Attention Mechanism
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Effective Approaches to Attention-based Neural Machine Translation

