一、Preview(Text Summarization)
1、What’s a good algorithm engineer?
算法基础
代码功底
业务理解和应用能力
良好的产品sense和业务owner意识
2、Level of Machine Learning Engineer
第一阶段:高效执行机器
这一阶段我认为算法工程师的核心竞争力是对模型的理解,对于模型不仅知其然,还得知其所以然。
第二阶段:算法选型和改造能力
这一阶段我认为算法工程师的核心竞争力在于代码功底好,一则知道各个模型的实现细节,二则能即快又好地实现idea。
第三阶段:业务抽象能力
他们像大夫,望闻问切,跟客户一起梳理出业务流程中的痛点,找到优化方式。不只是对行业整体的判断,还要对赛道
中的选手体检,有开药的能力。可以把对方的难言之隐梳理出来,定量、优先级排序,然后从整体到细节,一层层结构
化分解,最后进入具体执行。你要在传统行业创造新价值,就要搞清楚:什么东西制约了你的产能,制约了你的效率,
制约了你的利润率。
二、Language to word embedding
1、what is Out-of-vocabulary(OOV)
未登录词就是训练时未出现,测试时出现了的单词。在自然语言处理或者文本处理的时候,我们通常会有一个字词库(vocabulary)。这个vocabulary要么是提前加载的,或者是自己定义的,或者是从当前数据集提取的。假设之后你有了另一个的数据集,这个数据集中有一些词并不在你现有的vocabulary里,我们就说这些词汇是Out-of-vocabulary,简称OOV。
2、Word Embedding
简单的讲vector就是一个一维的数组,每一个词都变成一个vector。比如说先把一个词变到一个多维空间中,然后把所有的词都放在这个多维空间中。最大的好处是,这些词对计算机来说是categorical feature,像one-hot一样,两个词放在不同位置完全没有关系。如果用vector来表示,词与词之间的关系就可以用距离来表现。也就是说这些词对计算机来说本来是没有关系的,但通过vector转换之后,它们的距离代表了它们的关系,这也是比较好的帮助计算机去理解词之间关系的方法。
Word Embedding 实际上就是把词从词本身或从one-hot本身变成一个vector 的过程,Embedding就是你怎么去变换这个向量。
3、How do we represent the meaning of a word?
Meaning本身在字典的定义是:词背后的想法,或是某个人、文章、艺术品想要表达的想法。Meaning本身是个idea,它在大脑里面怎么存储的我们不知道,这个idea怎么让计算机系统去理解它,比较好的办法是把它变成一个vector。
词本身如果不做向量的变化,那计算机看起来是什么?如果两个词不一样,那就是一个分类的feature, 那我们就直接做one-hot,就是在出现的位置记为1,其他位置记为0,这样做显然是可以的,但是维度是十分大的,尤其是英文。比如说,你搜索电视大小其实和电视容量是一个意思,那计算机怎么知道电视大小和电视容量是同一个意思?包括你要查hotel和motel,其实是一个意思,如果用one-hot它们将在两个维度上,完全没有关系。如果把它变到一个比one-hot低维的,但每个位置上都是有浮点数的vector,而且这些浮点数的数值是有意义的,比如说两个词的浮点数值大小非常靠近,那这两个词就比较靠近,那这样学出来的vector 也是非常有意义的。
4、Problems with WordNet
Great but missing nuance(细微差别)
• e.g., “proficient” is listed as a synonym for “good” This is only
correct in some contexts
• Missing new meanings of words
• e.g., wicked, badass, nifty, wizard, genius, ninja, bombast
• Impossible to keep up-to-date!
Subjective
Requires human labor to create and adapt
Can’t compute accurate word similarity
5、Representing words as discrete symbols
In traditional NLP, we regard words as discrete symbols:
hotel, conference, motel – a localist representation
Such symbols for words can be represented by one-hot vectors:
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
Vector dimension = number of words in vocabulary (e.g., 5000,000)
6、Problem with words as discrete symbols
Example: in web search, if user searches for “Seattle motel”,
we would like to match documents containing “Seattle hotel”
But:
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
These two vectors are orthogonal
There is no natural notion of similarity for one-hot vectors!
Solution:
Could try to rely on WordNet’s list of synonyms to get similarity?
• But it is well-known to fail badly: incompleteness, etc
• Instead: learn to encode similarity in the vectors themselves
7、Question of N-gram
数据稀疏,难免会出现OOV的问题
• 随着 n 的增⼤,参数空间呈指数增⻓(维度灾难)
• 缺少⻓期依赖,只能建模到前 n-1 个词
• ⽆法表示⼀词多义(语义鸿沟)
8、Word Vector
分布表示(distributional representation)与分布式表示(distributed representation)
分布表示(distributional representation)
分布表示(distributional representation):是基于分布假设理论,利用共生矩阵来获取词的语义表示,可以看成是一类获取词表示的方法。
什么是分布假说呢?词是承载语义的最基本的单元,而传统的独热表示(one-hot represen-tation)仅仅将词符号化,不包含任何语义信息。如何将语义融入到词表示中?Harris 在 1954 年提出的分布假说(distributional hypothesis)为这一设想提供了理论基础:上下文相似的词,其语义也相似。
“这里的分布”与中文“统计分布”一词语义对应,描述的是上下文的概率分布。用上下文描述语义的表示方法(或基于分布假说的方法)都可以称作分布表示,如潜在语义分析模型(Latent Semantic Analysis, LSA)、潜在狄利克雷分配模型(Latent Dirichlet Allocation,LDA)等。
分布式表示(distributed representation)
分布式表示(distributed representation),描述的是把文本分散嵌入到另一个空间,一般从是从高维空间嵌入到低维空间。
“嵌入”是几个意思?感觉跟塞入、挤入差不多呀。
还真是这样。如词的独热表示(one-hot representation),首先是高维的,且在高维向量中只有一个维度描述了词的语义。多高?词典有多大就有多少维,怎么也得万把维度吧。
如何在低维空间表达一个词呢?目前流行的是通过矩阵降维或神经网络降维将语义分散存储到向量的各个维度中,这两类方法得到的向量空间是低维的一般都可以称作分布式表示,又称为词嵌入(word embedding)或词向量)。
看吧,这就把词的表示从高维(5000-20000)嵌入到低维(50-300)。what?300维也叫低维?!是的,你没学过相对论? ^_^
这里的分布式(distributed)是“分散”、“分配”的意思,与中文“分布式计算”一词语义对应,与之相对的是局部表示(local representation)。
词嵌入vs词向量
还是叫词嵌入好点。词向量容易绕人。从广义上讲,传统的词袋子模型也是用向量描述文本,也应当被称作词的向量表示,但是这种向量是高维稀疏的。在目前的NLP语境中,“词向量”特指由神经网络模型得到的低维实数向量表示。
9、Neural Probabilistic Language Model
10、Problems with Neural Probabilistic Language Model
• 有限的前文信息
• 计算量过大
• 词向量是副产品
三、Word2Vec
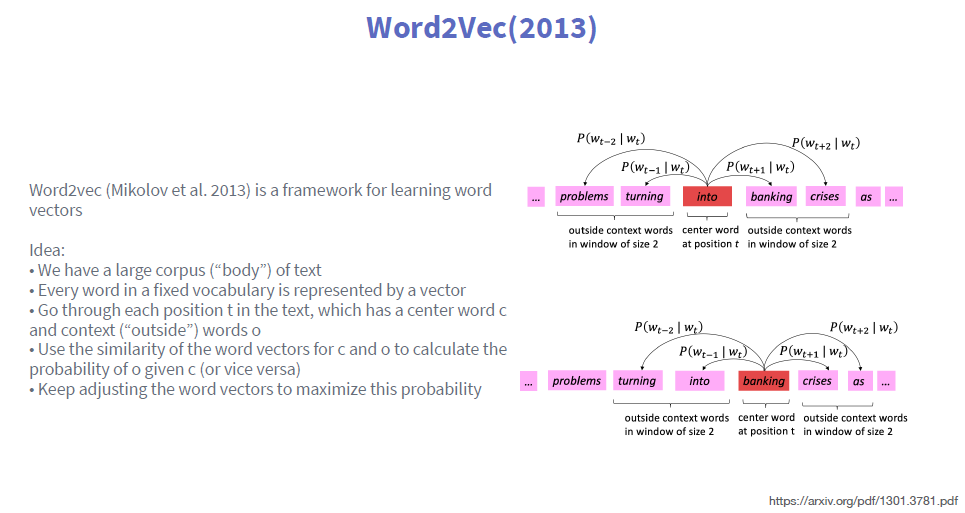
1、Word2Vec(2013)
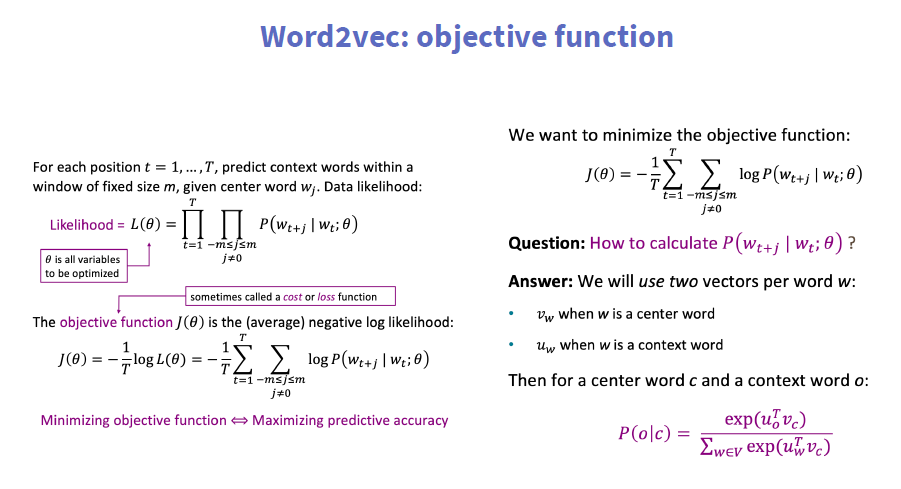
2、Word2vec: objective function
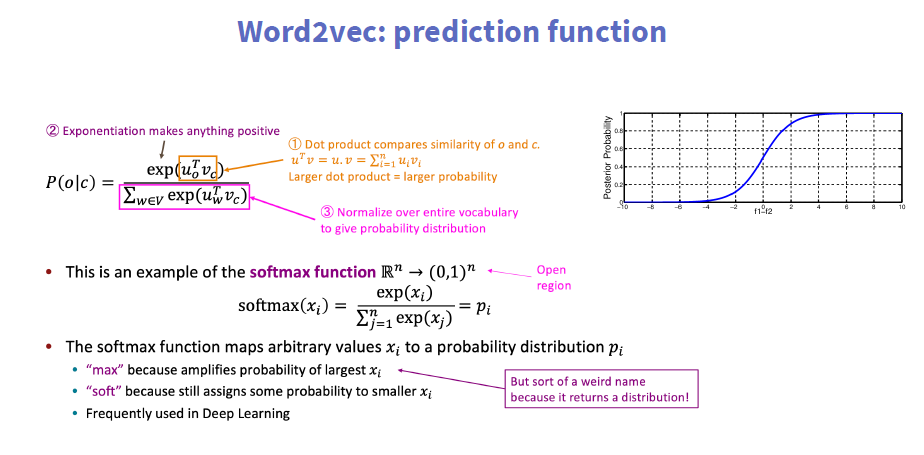
3、Word2vec: prediction function
4、CBOW&skip-gram
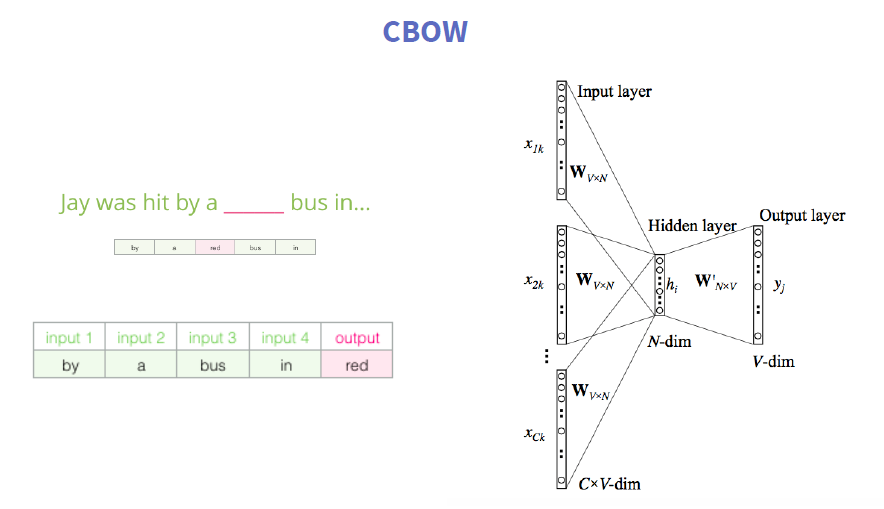
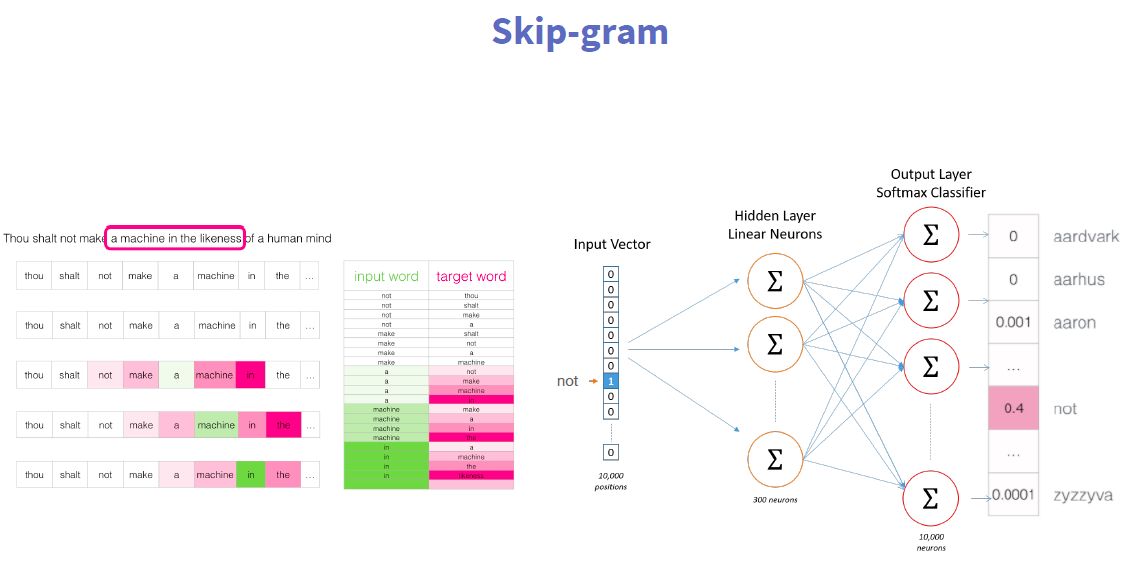
下面举一个Skip-Gram Model的例子,它的主要思想是:如果你能够拿到一些文本,可能是维基百科、百度百科的文章,很自然的有一些词就会出现在另一些词的附近,那我们在做Skip-Gram的过程实际就是在create 一个train data的过程,我们把文本拿来,把中间词作为x,两边的词作为label或是topic words,这两个词如果同时出现在附近,可以记为1,如果没有记为0。
这样的就可以得到一个train sample,这样的train sample都是一个pairs,这样就可以把文本变成很多个train sample,再返回刚才的模型,能很好的把Hidden Layer学出来。学到Hidden Layer之后这就一个embedding了,通过word Paris建立语言模型,然后每一个词再回来,本身还是一个one-hot encoding,再经过Hidden Layer weight matrix,会变成一些的word vector。
回溯总结一下,vector就是把词本身变成一个向量,怎么得到这个向量?刚才举到了用神经网络,Skip-Gram 建立train 数据,然后学到这个数据,然后Embedding实际上就是Hidden Layer weight matrix,通过Embedding就得到了向量。这是一个比较直接的,事实证明也是一个比较有效的办法。
5、Difference between Skip-Gram and CBOW
- Intuitively, the first task is much simpler, this implies a much faster convergence for CBOW than for Skip-gram, in the original paper (link below) they wrote that CBOW took hours to train, Skip-gram 3 days.
- For the same logic regarding the task difficulty, CBOW learn better syntactic relationships between words while Skipgram
is better in capturing better semantic relationships. - A final consideration to make deals instead with the sensitivity to rare and frequent words.
四、Hierarchical Softmax(H-Softmax)
1、Negative Sampling
刚刚有讲到每个词用one-hot encoding,然后用weight matrix与它相乘,假设我们想要得到的vector的size是300,输入字典的维度是10000,可以看到weight matrix 有300*10000个parameter,只有一个FC Layer就非常大了,所以不仅是weight matrix 这么大,每一次迭代都要把matrix更新一遍,这样整个学习过程的效率是十分低的。
比如说在10000个词中有很多和它是词义相近的,但绝大部分和它是没有关系的,数学的角度是正交的,所以它不需要每次都进行更新。所以Negative Sampling的核心:大量减少更新的内容,而且可以大量的减少训练损失,实际测量下来的结果也是非常好的。当然还要做一个词频,高频的词需要放到训练的过程当中去,低频的就不需要做了。
总结一下Word2Vec 是怎样一个流程:
Collect text data
Process text
Skip-Gram to generate word pair
Training embedding
Word2Vec
2、Vector Space Visualization
把它们全都变成vector之后下一步需要做什么?下一步最简单的做法就是把它们画出来。
当然之前例子中说到把每一个词变到300维,300维是人的肉眼是看不出来的,大家的物理世界只有3维,需要一些降维的方法,降维之后可以看到本来一些词是没有关系的,最后自动的group到一起。
比如说左上角12345678910的英语都到一起了,左下角和时间相关的都在一起了,右下角语文数学化学高考科目都到一起了,这是个比较有意思的事情,明显的看到这个学习的过程是比较有意义的,意思相近的词都在一起了。
还有一个点,word vector不仅仅是把词进行分类,而且词和词之间的距离也是有很强的关系。
比如说英语里面有基本级、比较级、最高级,如果看成一个向量,一个的比较级减去最高级和另外一个比较级减去另外一个最高级,下面的向量还是一样的。它不仅把词之间的分类学会了,词之间的关系也学会了。还有就是男人对应国王,女人对应什么?是皇后。这个也能学出来。所以Word2Vec的fundamental idea不是很难,但效果也是非常好的。

