Model-based DST and Rule-based Dialogue Policy
Model-based Dialogue State Tracking(DST)
Review
任务型对话系统(task-oriented dialogue system)的目标是协助用户完成特定的任务,比如订机票、打车、日程管理等。
一个典型的任务型对话系统可以分为四个模块:
自然语言理解(natural language understanding, NLU)、
对话状态追踪(dialogue state tracking, DST)、
策略学习(dialogue policy)
自然语言生成(natural language generation, NLG),
在这个过程中需要跟各种各样的数据库进行查询甚至更新等操作。
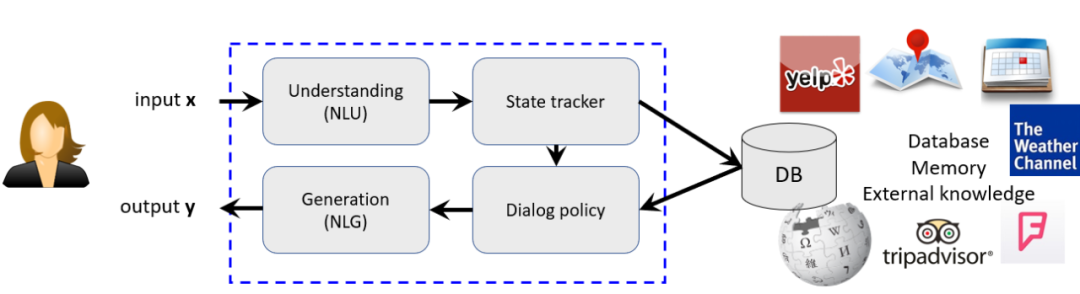
对话跟踪模块及其限制
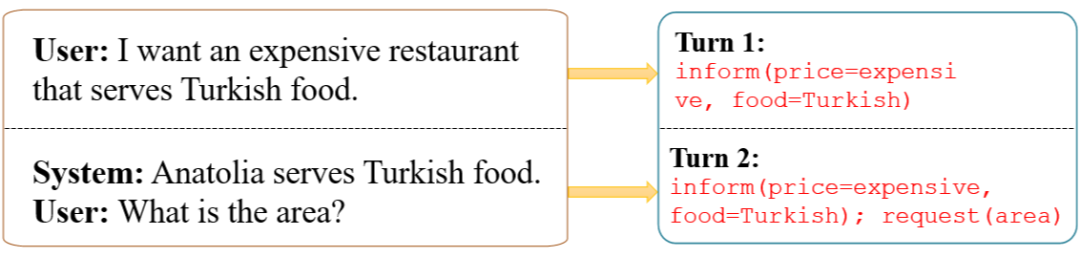
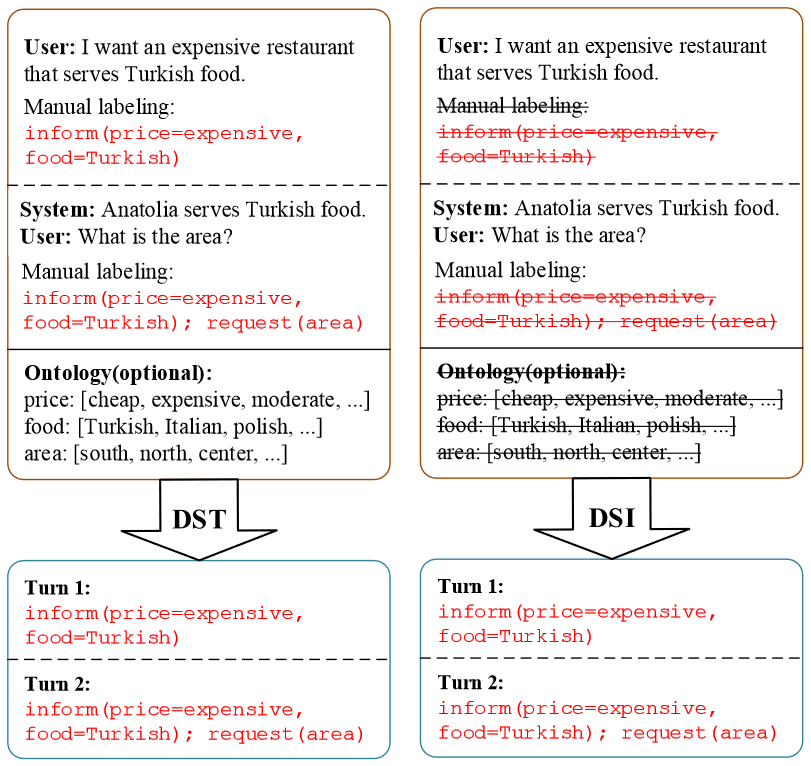
对话状态跟踪模块是任务型对话系统的一个核心模块,对话状态表示了用户在每轮对话所寻求的内容的关键信息,它是从对话开始到当前轮的所有信息的累积,表示形式是一些 slot-value pairs 的集合,inform 表示用户对所寻求的内容的限制,request 表示用户想要寻求哪些内容。
What’s DST
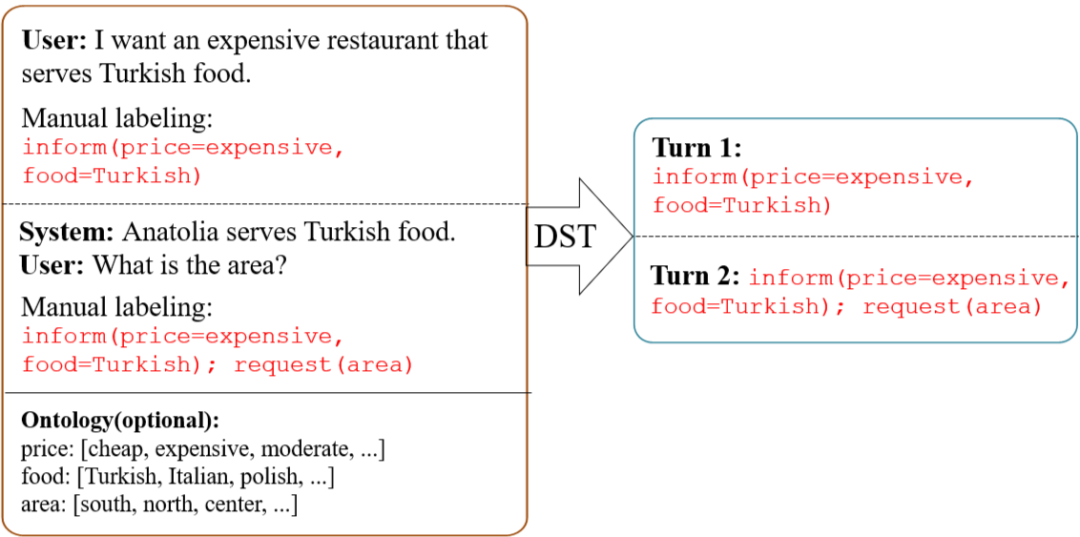
DST 的做法是先通过 NLU 模块对用户对话进行意图识别和槽位解析,然后将结果输入到 DST 模块中,由 DST 模块处理 NLU 模块带来的一些不确定性,得到最终的对话状态。目前越来越多的工作直接通过一个端到端的 DST 模型来直接处理用户对话(以及历史对话记录)得到当前的对话状态,如图 3 所示
延申知识点:DSI
Dialogue State Induction Using Neural Latent Variable Models
基于神经隐变量模型的对话状态推理
论文链接:https://www.ijcai.org/Proceedings/2020/0532.pdf
代码链接:https://github.com/taolusi/dialogue-state-induction
PPT链接:https://taolusi.github.io/qingkai_min/assets/pdf/20-ijcai-dsi_slides.pdf
视频接:https://www.bilibili.com/video/BV1fV41127tq
论文总结:
对话状态跟踪模块是任务型对话系统中的核心部件,目前主流的对话状态跟踪的方法需要在大量人工标注的数据上进行训练。然而,对于现实世界中的各种客户服务对话系统来说,人工标注的过程存在代价高、标注慢、错误率高以及难以覆盖数量庞大的不同领域等问题。
基于这些问题,提出了一个新的任务:对话状态推理 (dialogue state induction, DSI),任务的目标是从大量的生对话语料中自动推理得到对话状态,并能更好的用于下游任务比如策略学习和对话生成。
DSI 与 DST 的区别如图 5 所示,和 DST 相似的是,DSI 的输出也是 slot-value pairs 形式的对话状态,不同的是,在训练过程中 DST 依赖于对话语料以及人工标注的对话状态,而 DSI 不依赖于人工标注,可以在生对话中自动生成 slot-value pairs。
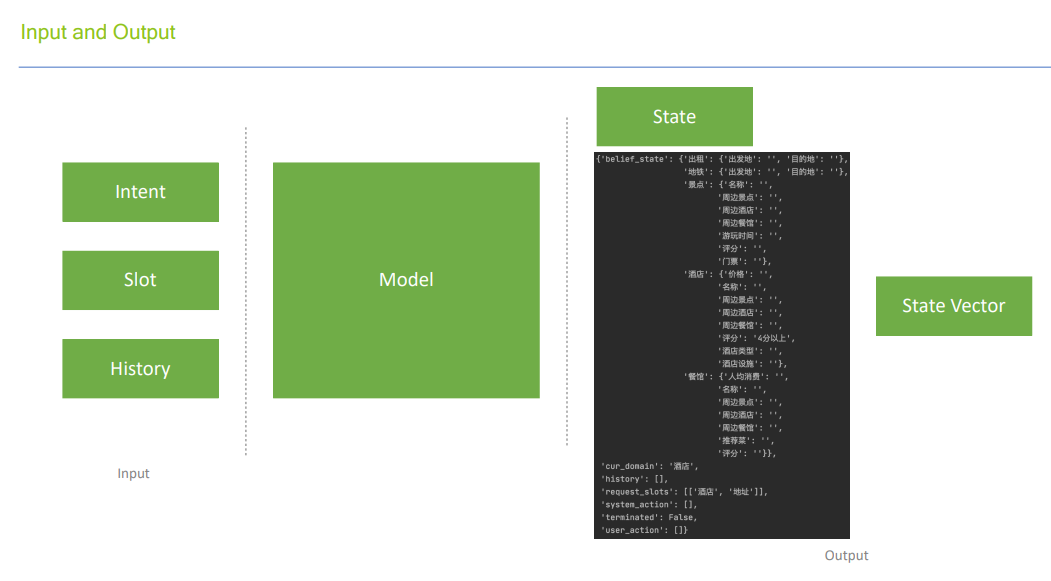
Input and Output
BERT-based model for DST(基于Bert模型的对话跟踪)
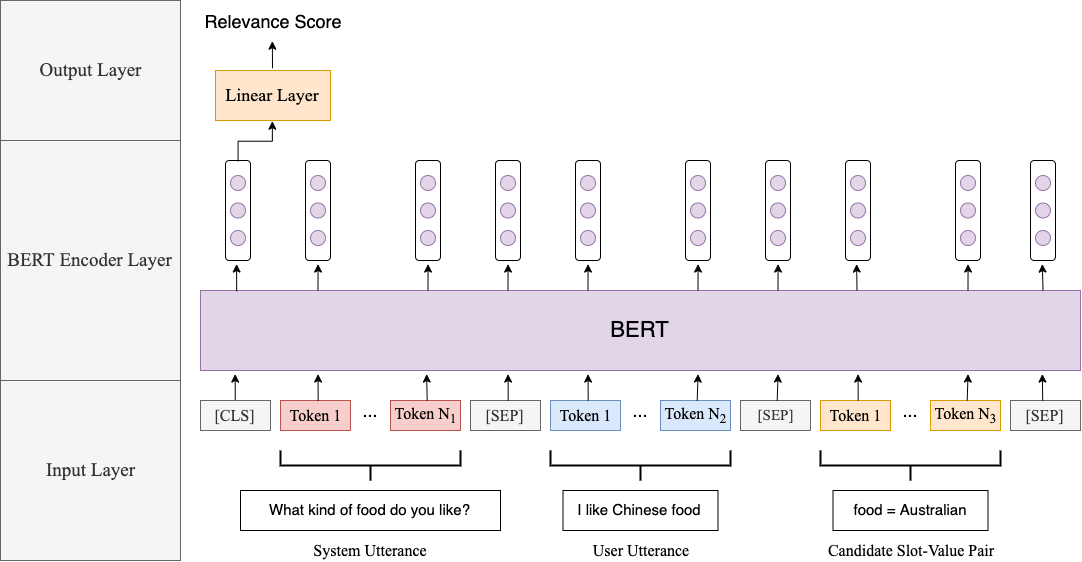
上图显示了我们提议的BERT在DST中的应用。在较高的级别上,给定一个对话框上下文和一个候选槽位值对,我们的模型将输出一个得分,以指示该候选对象的相关性。换句话说,该方法类似于句子对的分类任务。
第一个输入对应于对话框上下文,它由上一回合的系统话语(system utterance)和当前回合的用户话语(user utterance)组成。这两个话语由[SEP] Token分隔。
第二个输入是候选的slot-value对。 我们简单地将候选对表示为标记序列(单词或单词片段)。 将两个输入段连接成一个单个令牌序列,然后简单地传递给BERT以获取输出向量($h_1,h_2···,h_M$)。 在此,$M$表示输入令牌的总数(包括特殊标记,例如[CLS]和[SEP])。
基于对应于第一特殊令牌-[CLS](即h1)的输出矢量,候选时隙值对相关的概率为:
其中变换矩阵W和偏置项b是模型参数,σ表示Sigmoid函数。 它将分数压缩到0到1之间的概率。
在每个Turn中,使用所提出的基于BERT的模型来估计每个候选slot-value对的概率值。 此后,仅将预测概率值至少为0.5的slot-value对选择出来作为该turn的最终预测值。 为了获得当前回合的对话状态,我们使用新预测的槽值对来更新上一回合状态下的对应值。 例如,假设用户在当前回合中指定了一个food = chinese的餐馆。 如果对话框状态没有现有的food参数,则可以将food = chinese添加到对话框状态。 如果以前指定过food = korean,我们将其替换为food = chinese。
论文链接:https://arxiv.org/pdf/1910.12995.pdf
代码链接:https://github.com/laituan245/BERT-Dialog-State-Tracking
代码链接:https://github.com/BSlience/BERT-DST/
Further DST
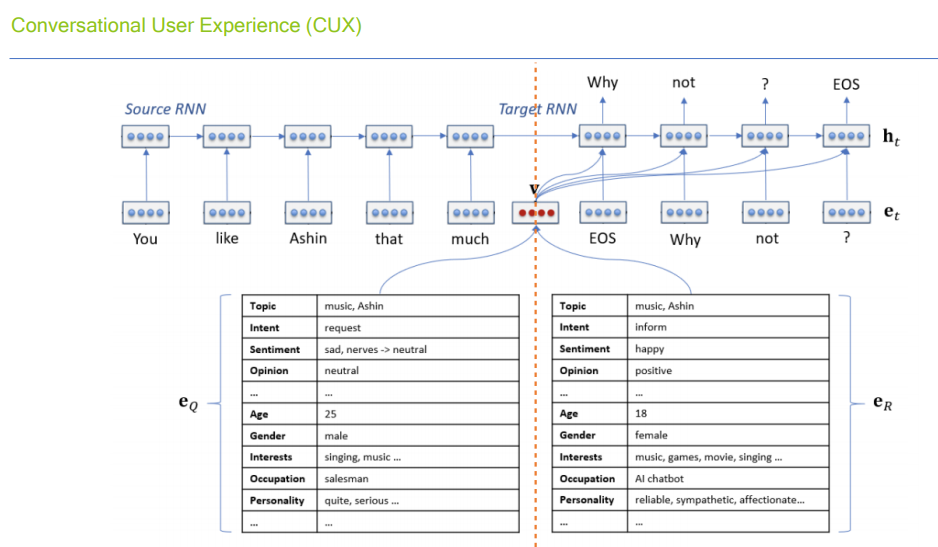
Rule-based Dialogue Policy(DP)
Review
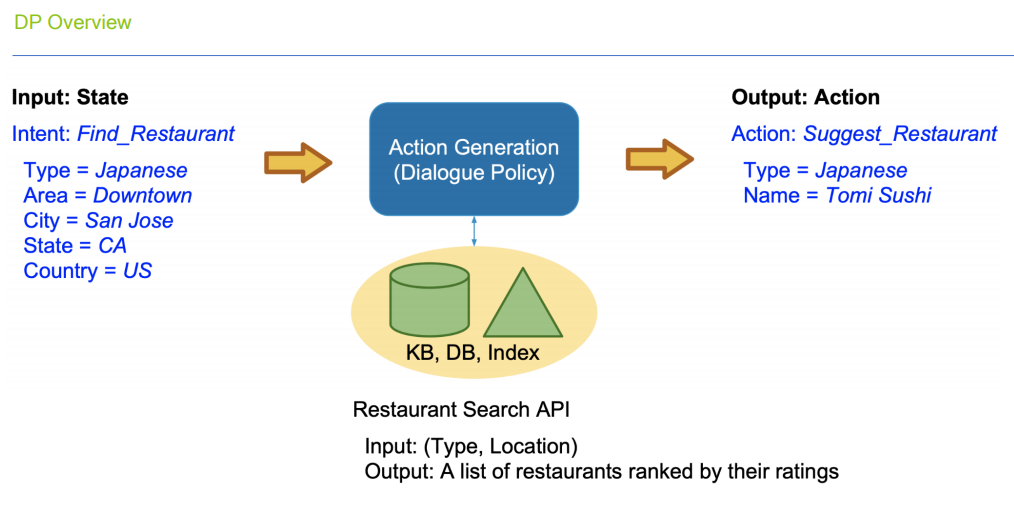
Action
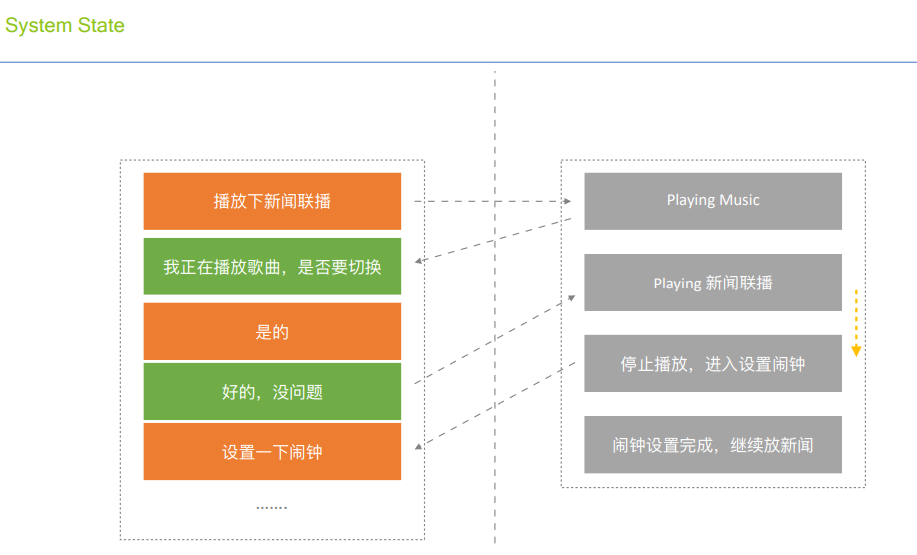
Dialogue Policy: Rule-Based, Change Slot, Repeat Intent, System state
RASA Policy
![]()
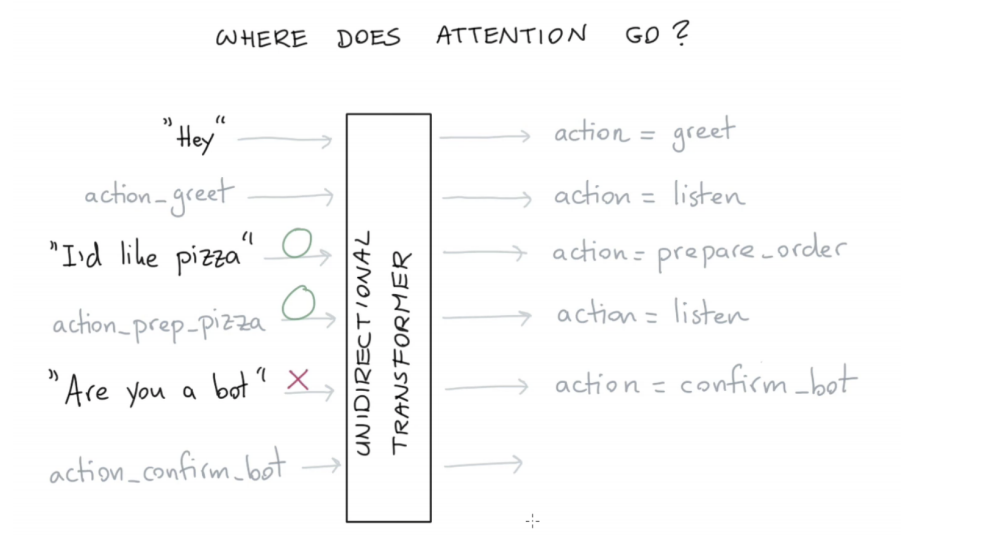
详细可参考youtube视频:
参考:
Dialogue State Induction Using Neural Latent Variable Models

