对话系统导论学习分享
一、对话系统的分类
1、模块化对话系统,即分模块串行处理对话任务,每个模块负责特定的任务,并将结果传递给下一个模块。在具体的实现上,可以针对任一模块采用基于规则的人工设计方式,或者基于数据驱动的模型方式。
2、端到端的对话系统,由输入直接到输出的端到端对话系统,忽略中间过程,采用数据驱动的模型实现。
Task Type
1、Task-Oriented/Task-completed Bot
2、QA(Question Answering) Bot
3、Chatbot/Chitchat/Social Chat
Methodology of Building bots (机器人程序的方法论)
Categories of Conversational AI (AI会话的分类)
1、Chatbot(闲聊型对话,微软小冰)
闲聊型对话大多为开放域的对话,主要以满足用户的情感需求为主,通过产生有趣、富有个性化的答复内容,与用户进行互动。
2、QA Bot(问答型对话, 搜索)
主要为一问一答的形式,机器人对用户提出的问题进行解析,在知识库已有的内容中查找并返回正确答案。对于机器人而言,每次问答均是独立的,与上下文信息无关。
3、Task-oriented Bot (面向任务的机器人,多轮对话系统)
主要指机器人为满足用户某一需求(带有明确目的)而产生的多轮对话(如查流量,查话费,订餐,订票,咨询等任务型场景),机器人通过理解、澄清等方式确定用户意图,继而通过答复、调用API等方式完成该任务。在该任务内,机器人需要理解上下文信息并作出下一步的动作。
由于用户的需求较为复杂,通常情况下需分多轮互动,用户也可能在对话过程中不断修改与完善自己的需求,任务型机器人需要通过询问、澄清和确认来帮助用户明确目的。
任务型对话系统也常被称为多轮对话系统,目前工业界有两种实现方式,一种是基于规则的实现方式,另一种则是基于End-to-End的实现方式。基于End-to-End的实现方式试图训练一个从用户端自然语言输入到机器端自然语言输出的整体映射关系,从而提高系统的灵活性与可拓展性,但该模型对数据的质量和数量要求非常高,并且存在不可解释性,因此,目前工业界大多采用基于规则的实现方式。本文以下内容中所提到的任务型对话系统也是基于规则的实现方式。
Category of QA
KB-QA
KB(Knowledge Base)
KG(Knowledge Graph)
Text-QA
Methodology on KB
Semantic Parsing (语义解析)
Information Extraction (信息提取)
Embedding-based Methods (基于嵌入的方法)
Neural Methods (神经网络方法)
System Action
User Action
State
User State
System State
NLG
Template-based
Model-based
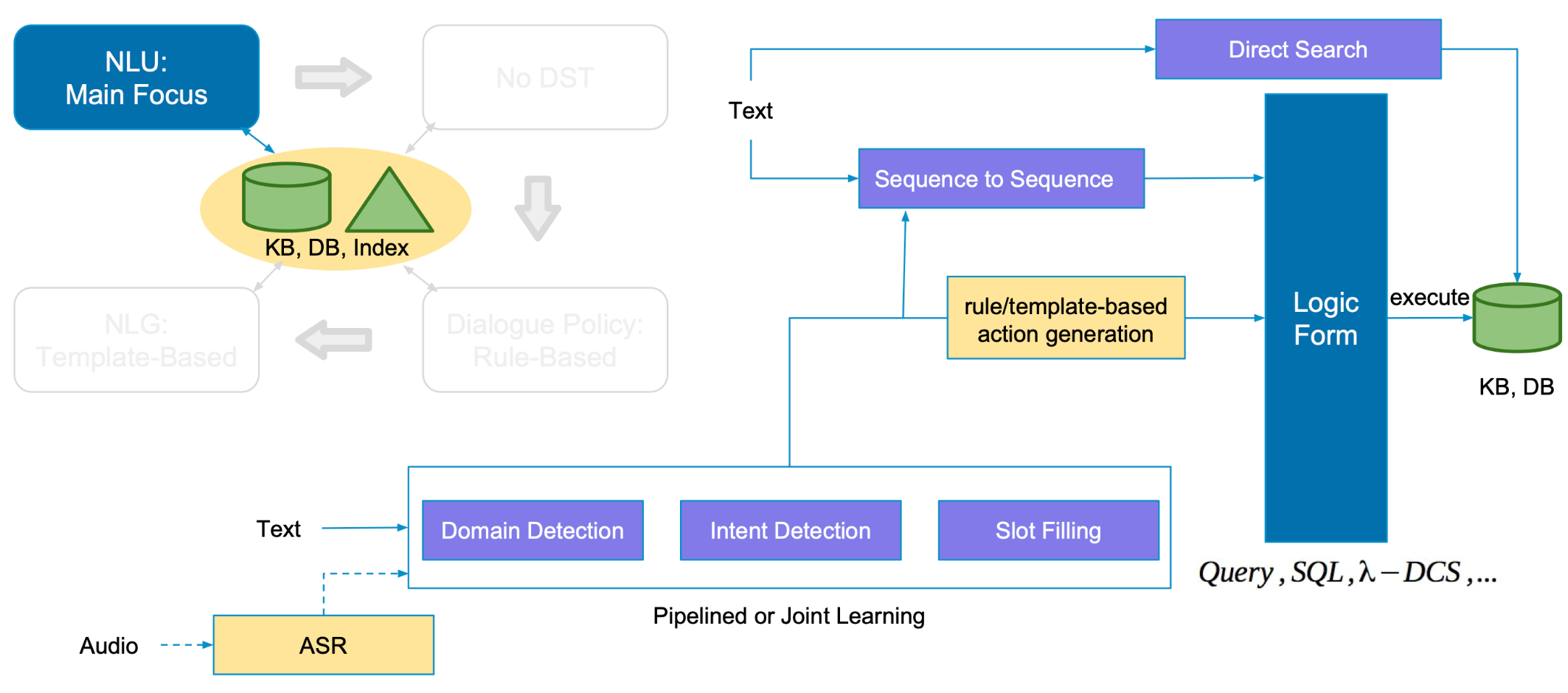
二、Modular/Pipeline Approach Architecture【模块化/管道方法架构】
主要组成部分【参考PPT第34页】
Dialogue Input(对话输入) —>
Natural Language Understanding(NLU) —>
Dialogue Manager(DM)
Dialogue State Tracking(DST)—>
Action Generation(Dialogue Policy) —>
Natural Language Generation(NLG) —>
Dialogue Output(对话输出)
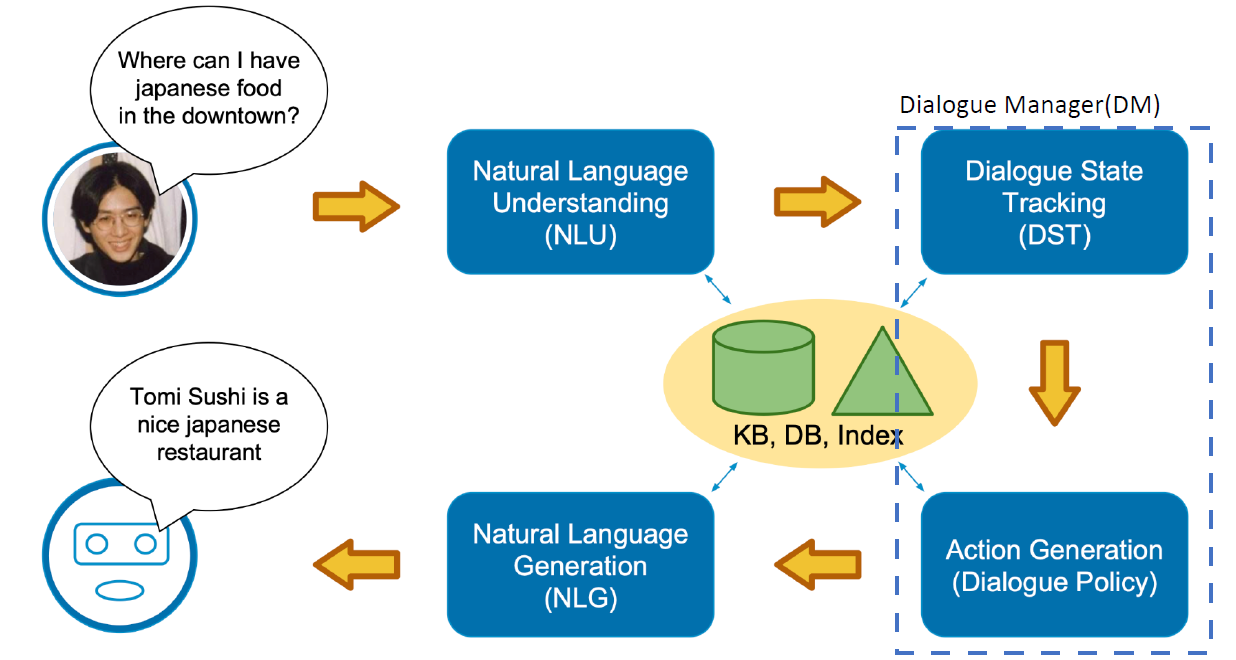
2.1 NLU(Natural Language Understanding)自然语言理解
什么是NLU
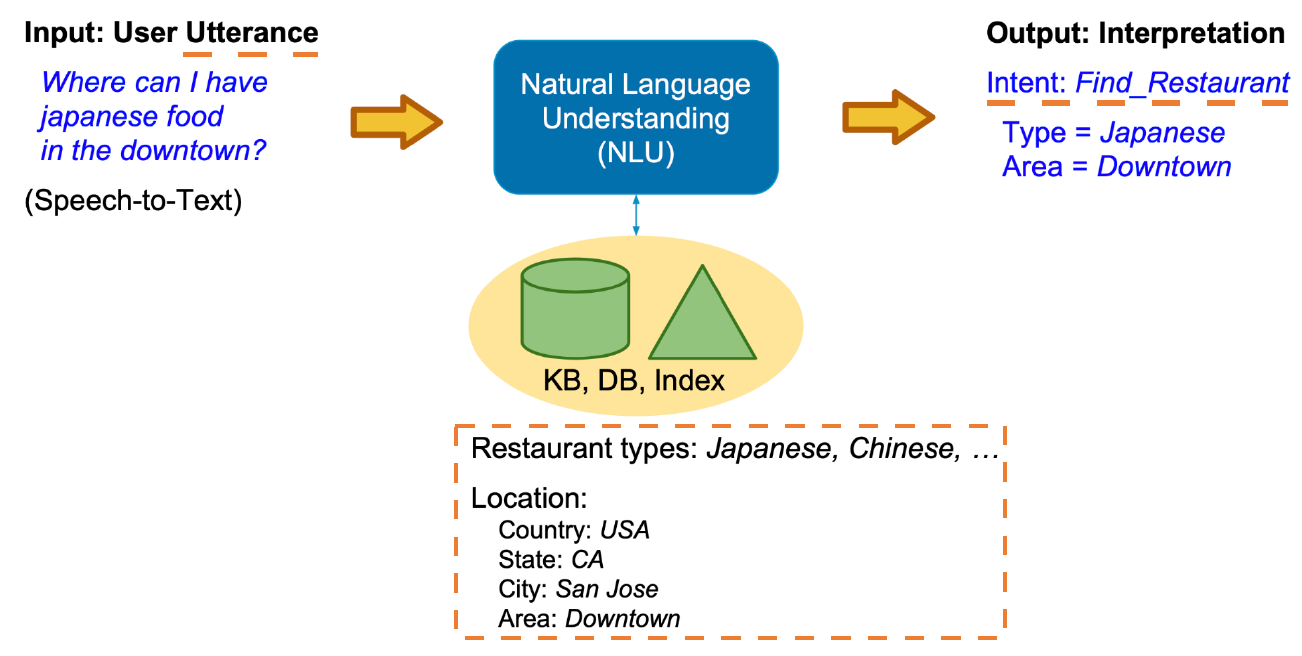
NLU是将用户输入的自然语言语句映射为机器可读的结构化语义表述,这种结构化语义一般由两部分构成,分别是用户意图(user intention)和槽值(slot-value)。
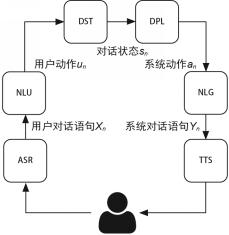
对面向任务的对话系统来说,NLU模块的主要任务是将用户输入的自然语言映射为用户的意图和相应的槽位值。因此,NLU模块的输入是讲用户对话语句$X_n$,输出是解析$X_n$后得到的用户动作$U_n$,该模块涉及的主要技术是意图识别和槽位填充,这两种技术分别对应用户动作的两项结构化参数,即意图和槽位。
【做好NLU需要掌握两项关键技能:意图识别和实体提取】
下面主要讨论如何针对面向任务的对话系统设计NLU模块,包括针对特定任务定义意图和相应的槽位,以及后续从用户的输入中获取任务目标的意图识别方法和对应的槽位填充方法。
(1)意图和槽位的定义
意图和槽位共同构成了“用户动作”,机器是无法直接理解自然语言的,因此用户动作的作用便是将自然语言映射为机器能够理解的结构化语义表示。
意图识别,也被称为SUC(Spoken Utterance Classification),顾名思义,是将用户输入的自然语言会话进行划分,类别(classification)对应的就是用户意图。例如“今天天气如何”,其意图为“询问天气”。自然地,可以将意图识别看作一个典型的分类问题。意图的分类和定义可参考ISO-24617-2标准,其中共有56种详细的定义。面向任务的对话系统中的意图识别通常可以视为文本分类任务。同时,意图的定义与对话系统自身的定位和所具有的知识库有很大关系,即意图的定义具有非常强的领域相关性。
槽位,即意图所带的参数。一个意图可能对应若干个槽位,例如询问公交车路线时,需要给出出发地、目的地、时间等必要参数。以上参数即“询问公交车路线”这一意图对应的槽位。语义槽位填充任务的主要目标是在已知特定领域或特定意图的语义框架(semantic frame)的前提下,从输入语句中抽取该语义框架中预先定义好的语义槽的值。语义槽位填充任务可以转化为序列标注任务,即运用经典的IOB标记法,标记某一个词是某一语义槽的开始(begin)、延续(inside),或是非语义槽(outside)。
要使一个面向任务的对话系统能正常工作,首先要设计意图和槽位。意图和槽位能够让系统知道该执行哪项特定任务,并且给出执行该任务时需要的参数类型。为了方便与问答系统做异同对比,我们依然以一个具体的“询问天气”的需求为例,介绍面向任务的对话系统中对意图和槽位的设计。
用户输入示例:“今天上海天气怎么样”
用户意图定义:询问天气,Ask_Weather
槽位定义
槽位一:时间,Date
槽位二:地点,Location
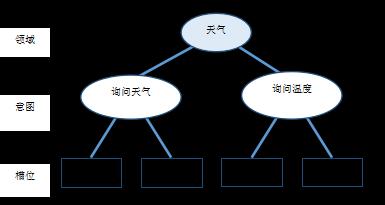
“询问天气”的需求对应的意图和槽位如下图所示。
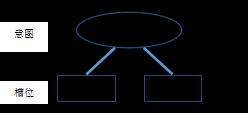
在上述示例中,针对“询问天气”任务定义了两个必要的槽位,它们分别是“时间”和“地点”。
对于一个单一的任务,上述定义便可解决任务需求。但在真实的业务环境下,一个面向任务的对话系统往往需要能够同时处理若干个任务,例如气象台除了能够回答“询问天气”的问题,也应该能够回答“询问温度”的问题。
对于同一系统处理多种任务的复杂情况,一种优化的策略是定义更上层的领域,如将“询问天气”意图和“询问温度”意图均归属于“天气”领域。在这种情况下,可以简单地将领域理解为意图的集合。定义领域并先进行领域识别的优点是可以约束领域知识范围,减少后续意图识别和槽位填充的搜索空间。此外,对于每一个领域进行更深入的理解,利用好任务及领域相关的特定知识和特征,往往能够显著地提升NLU模块的效果。据此,对图2的示例进行改进,加入“天气”领域。
用户输入示例
1、“今天上海天气怎么样”
2、“上海现在气温多少度”
领域定义:天气,Weather
用户意图定义
1、询问天气,Ask_Weather
2、询问温度,Ask_Temperature
槽位定义
槽位一:时间,Date
槽位二:地点,Location
改进后的“询问天气”的需求对应的意图和槽位如下图所示。
(2)意图识别和槽位填充
做好意图和槽位的定义后,需要从用户输入中提取用户意图和相应槽对应的槽值。意图识别的目标是从用户输入的语句中提取用户意图,单一任务可以简单地建模为一个二分类问题,如“询问天气”意图,在意图识别时可以被建模为“是询问天气”或者“不是询问天气”二分类问题。当涉及需要对话系统处理多种任务时,系统需要能够判别各个意图,在这种情况下,二分类问题就转化成了多分类问题。
槽位填充的任务是从自然语言中提取信息并填充到事先定义好的槽位中,例如在图2中已经定义好了意图和相应的槽位,对于用户输入“今天上海天气怎么样”系统应当能够提取出“今天”和“上海”并分别将其填充到“时间”和“地点”槽位。基于特征提取的传统机器学习模型已经在槽位填充任务上得到了广泛应用。近年来,随着深度学习技术在自然语言处理领域的发展,基于深度学习的方法也逐渐被应用于槽位填充任务。相比于传统的机器学习方法,深度学习模型能够自动学习输入数据的隐含特征。例如,将可以利用更多上下文特征的最大熵马尔可夫模型引入槽位填充的过程中[8],类似地,也有研究将条件随机场模型引入槽位填充。
例子:在生活中,如果想要订机票,人们会有很多种自然的表达:
“订机票”;
“有去上海的航班么?”;
“看看航班,下周二出发去纽约的”;
“要出差,帮我查下机票”;
等等等等
“自然的表达” 有无穷多的组合(自然语言)都是在代表 “订机票” 这个意图的。而听到这些表达的人,可以准确理解这些表达指的是“订机票”这件事。
而要理解这么多种不同的表达,对机器是个挑战。在过去,机器只能处理“结构化的数据”(比如关键词),也就是说如果要听懂人在讲什么,必须要用户输入精确的指令。
所以,无论你说“我要出差”还是“帮我看看去北京的航班”,只要这些字里面没有包含提前设定好的关键词“订机票”,系统都无法处理。而且,只要出现了关键词,比如“我要退订机票”里也有这三个字,也会被处理成用户想要订机票。

自然语言理解这个技能出现后,可以让机器从各种自然语言的表达中,区分出来,哪些话归属于这个意图;而那些表达不是归于这一类的,而不再依赖那么死板的关键词。比如经过训练后,机器能够识别“帮我推荐一家附近的餐厅”,就不属于“订机票”这个意图的表达。
并且,通过训练,机器还能够在句子当中自动提取出来“上海”,这两个字指的是目的地这个概念(即实体);“下周二”指的是出发时间。
这样一来,看上去“机器就能听懂人话啦!”。

NLU的应用场景
几乎所有跟文字语言和语音相关的应用都会用到 NLU,如机器翻译、机器客服、智能音箱。
例:
“我冷了”
机器:帮您把空调调高1度
用户并没有提到空调,但是机器需要知道用户的意图——空调有点冷,需要把温度调高。
NLU的难点
语言的多样性:组合方式非常灵活,字、词、短语、句子、段落…不同的组合可以表达出很多的含义
给唱一首大王叫我来巡山;
放音乐大王叫我来巡山;
语言的歧义性:如果不联系上下文,缺少环境的约束,语言有很大的歧义性
我要去拉萨
- 需要火车票?
- 需要飞机票?
- 想听音乐?
- 还是想查找景点?
语言的鲁棒性:自然语言在输入的过程中,尤其是通过语音识别获得的文本,会存在多字、少字、错字、噪音等问题。例如:
大王叫我来新山
大王叫让我来巡山
大王叫我巡山
语言的知识依赖:语言是对世界的符号化描述,语言天然连接着世界知识,例如:
苹果
除了表示水果,还可以表示科技公司
7天
可以表示时间,也可以表示酒店名
晚安
有一首歌也叫《晚安》
语言的上下文:上下文的概念包括很多种:对话的上下文、设备的上下文、应用的上下文、用户画像…
U:买张火车票
A:请问你要去哪里?
U:宁夏
U:来首歌听
A:请问你想听什么歌?
U:宁夏
NLU 的实现方式
1、基于规则的方法
早期大家通过总结规律来判断自然语言的意图,常见的方法有:CFG、JSGF等。
2、基于统计的方法
后来出现了基于统计学的 NLU 方式,常见的方法有:SVM、ME等。
3、基于深度学习的方法
随着深度学习的爆发,CNN、RNN、LSTM 都成为了最新的”统治者”。到了2019年,BERT 和 GPT-2 的表现震惊了业界,他们都是用了 Transformer,Transformer是目前「最先进」的方法。
2.2 Dialogue State Tracking
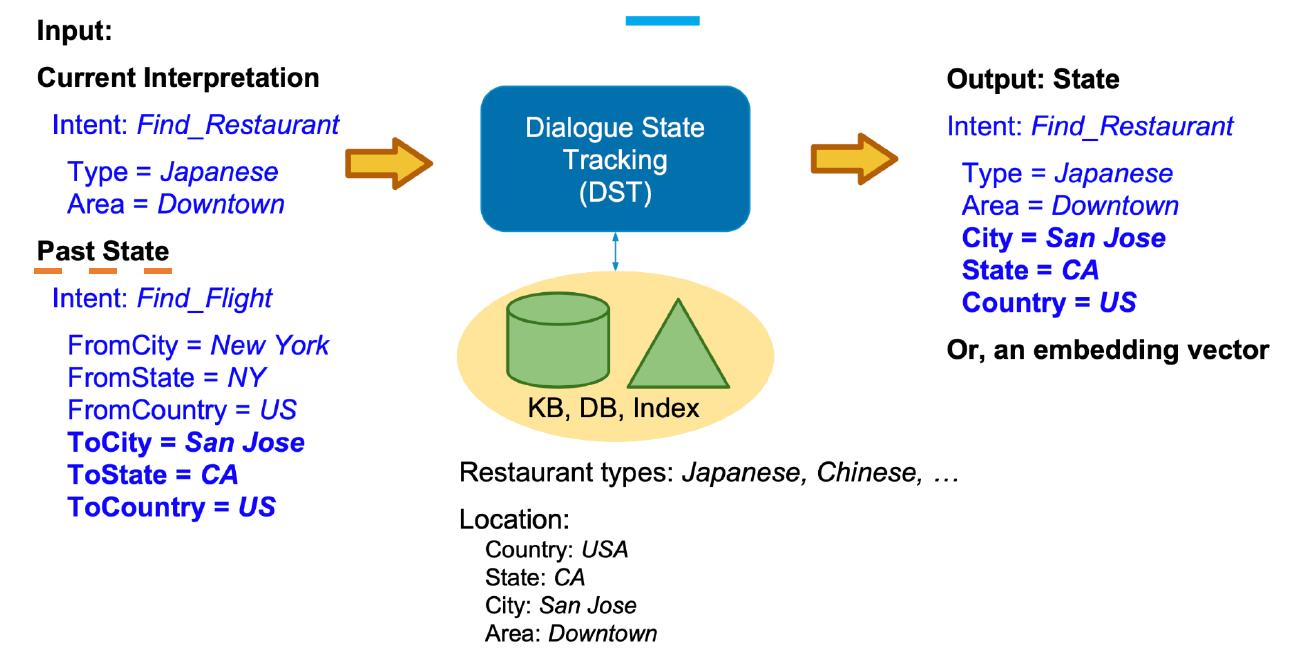
DST:这一模块的目标是追踪用户需求并判断当前的对话状态。该模块以多轮对话历史、当前的用户动作为输入,通过总结和推理理解在上下文的环境下用户当前输入自然语言的具体含义。对于对话系统来说,这一模块有着重大意义,很多时候需要综合考虑用户的多轮输入才能让对话系统理解用户的真正需求。
DST模块以当前的用户动作$U_n$、$n-1$前轮的对话状态和相应的系统动作作为输入,输出是DST模块判定得到的当前对话状态$S_n$。
对话状态的表示(DST-State Representation)通常由以下3部分构成。
(1)目前为止的槽位填充情况。
(2)本轮对话过程中的用户动作。
(3)对话历史。
其中,槽位的填充情况通常是最重要的状态表示指标。
2.3 Action Generation(Dialogue Policy)
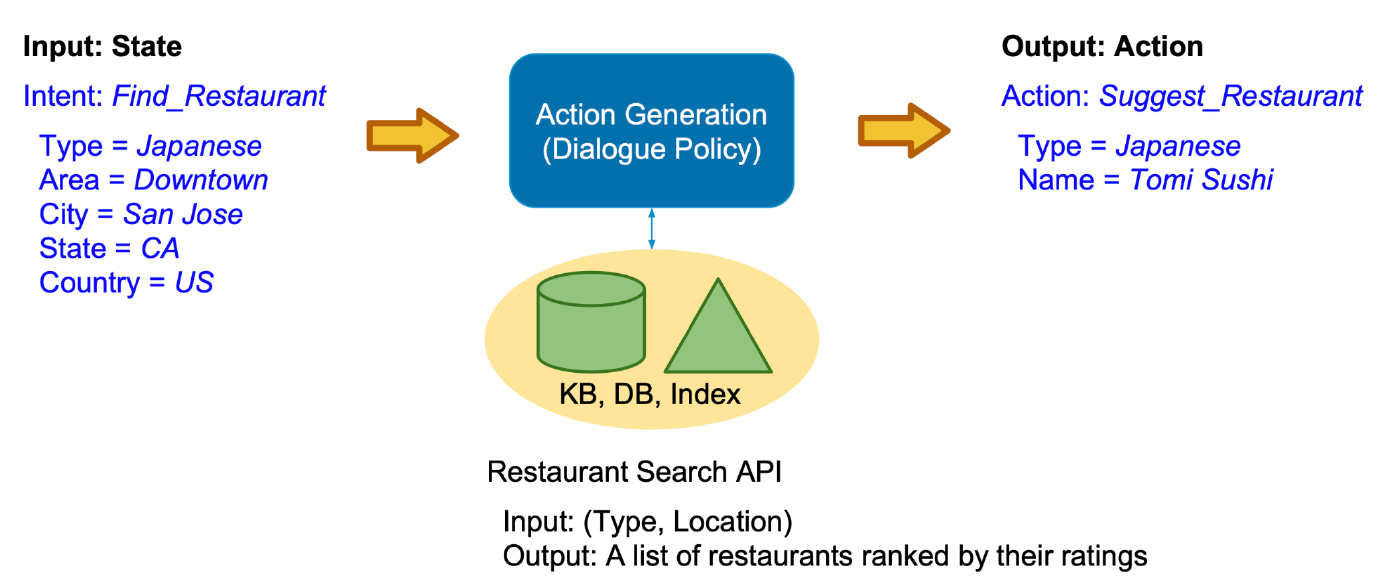
DPL:也被称为对话策略优化(optimization),根据当前的对话状态,对话策略决定下一步执行什么系统动作。系统行动与用户意图类似,也由意图和槽位构成。
DPL模块的输入是DST模块输出的当前对话状态$S_n$,通过预设的对话策略,选择系统动作$a_n$作为输出。下面结合具体案例介绍基于规则的DPL方法,也就是通过人工设计有限状态自动机的方法实现DPL。
案例:询问天气
以有限状态自动机的方法进行规则的设计,有两种不同的方案:一种以点表示数据,以边表示操作;另一种以点表示操作,以边表示数据,这两种方案各有优点,在具体实现时可以根据实际情况进行选择。
2.4 NLG(Natural Language Generating)自然语言生成
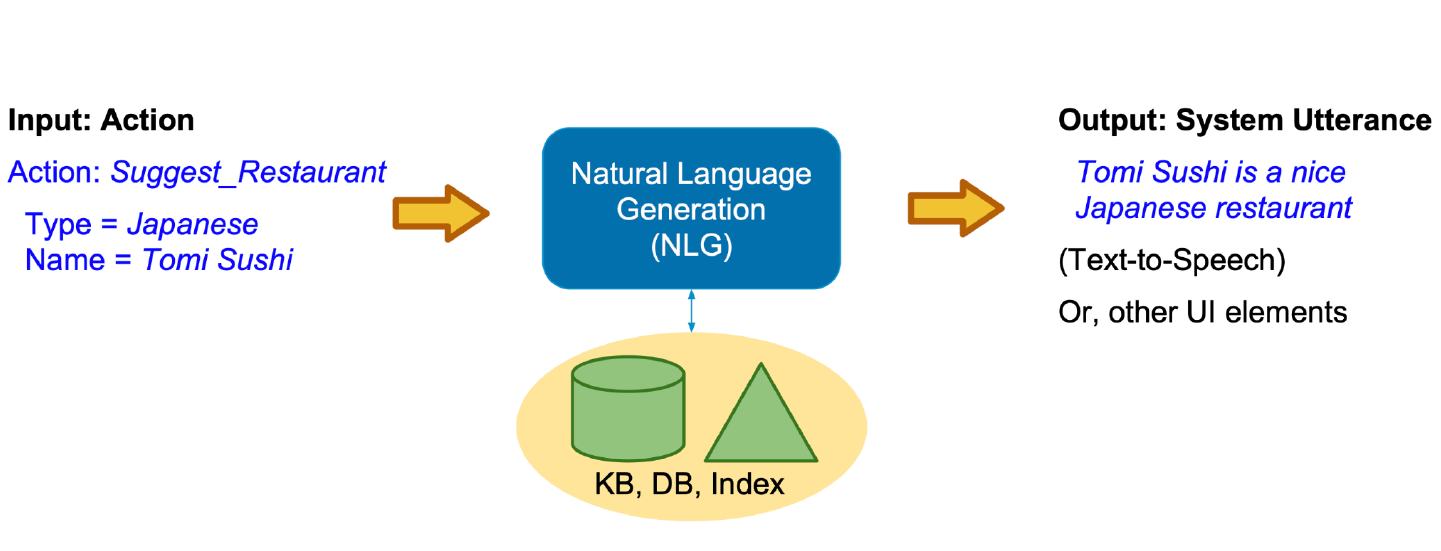
NLG模块的输入是DPL模块输出的系统动作$a_n$,输出是系统对用户输入$X_n$的回复$Y_n$。
目前,NLG模块仍广泛采用传统的基于规则的方法,下表给出了3个示例规则的定义。根据规则可以将各个系统动作映射成自然语言表达。

对于NLG,则是将对话策略模块选择的系统动作(非语言格式的数据)转换成人类可以理解的语言格式,如文章,报告等。
什么是NLG
NLG 是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
NLG的2种方式
text – to – text:文本到语言的生成
data – to – text :数据到语言的生成
NLG的3个Level
简单的数据合并:自然语言处理的简化形式,这将允许将数据转换为文本(通过类似Excel的函数)。为了关联,以邮件合并(MS Word mailmerge)为例,其中间隙填充了一些数据,这些数据是从另一个源(例如MS Excel中的表格)中检索的。
模板化的 NLG :这种形式的NLG使用模板驱动模式来显示输出。以足球比赛得分板为例。数据动态地保持更改,并由预定义的业务规则集(如if / else循环语句)生成。
高级 NLG :这种形式的自然语言生成就像人类一样。它理解意图,添加智能,考虑上下文,并将结果呈现在用户可以轻松阅读和理解的富有洞察力的叙述中。
NLG的6个步骤
第一步:内容确定 – Content Determination
作为第一步,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 – Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达「什么时间」「什么地点」「哪2支球队」,然后再表达「比赛的概况」,最后表达「比赛的结局」。
第三步:句子聚合 – Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 – Lexicalisation
当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 – Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于“REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 – Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
NLG 的3种典型应用
NLG 的不管如何应用,大部分都是下面的3种目的:
- 能够大规模的产生个性化内容
- 帮助人类洞察数据,让数据更容易理解
- 加速内容生产
三、Single-Turn Question Answering Systems
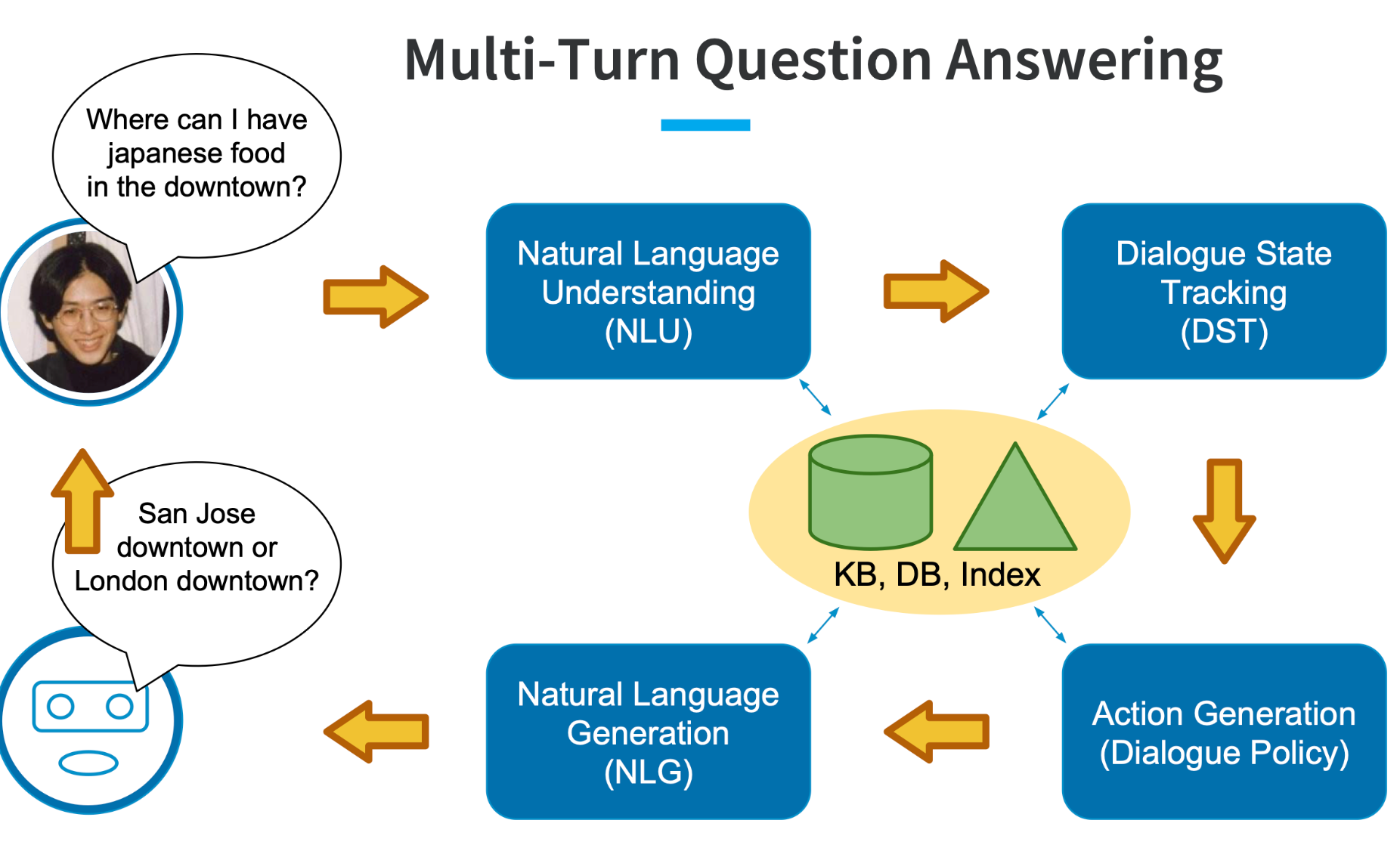
四、Multi-Turn Question Answering
五、其他补充要点
关于Transformer:
《BERT大火却不懂Transformer?读这一篇就够了》
《why Self-Attention?A Targeted Evaluation of Neural Machine Translation Architectures》
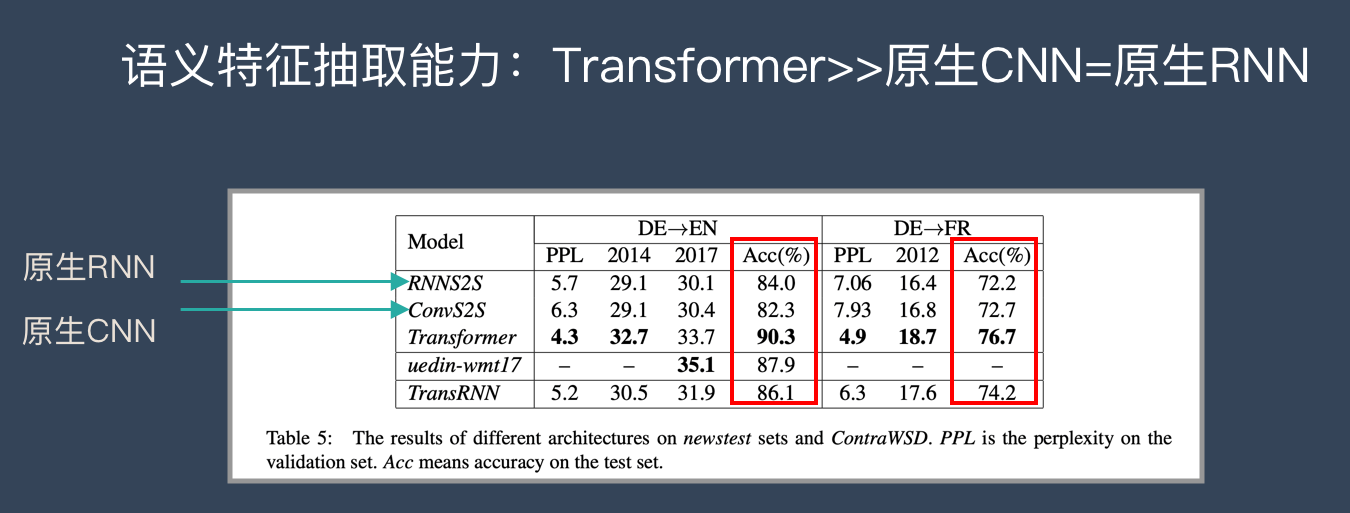
从语义特征提取能力来说,Transformer在这方面的能力非常显著地超过RNN和CNN(在考察语义类能力的任务WSD中,Transformer超过RNN和CNN大约4-8个绝对百分点),RNN和CNN两者能力差不太多。
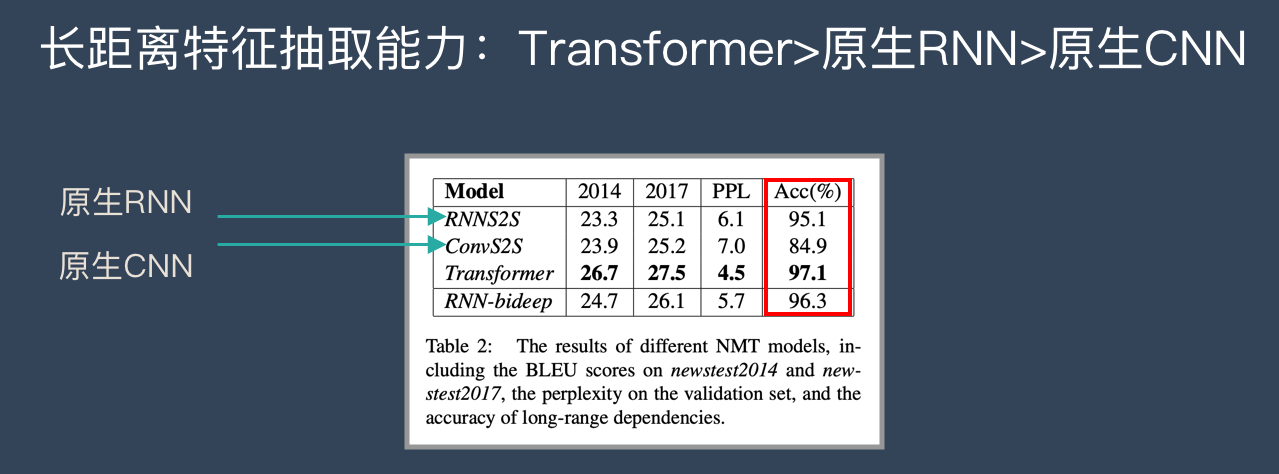
原生CNN特征抽取器在这方面极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型(尤其在主语谓语距离小于13时),能力由强到弱排序为Transformer > RNN >> CNN; 但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。
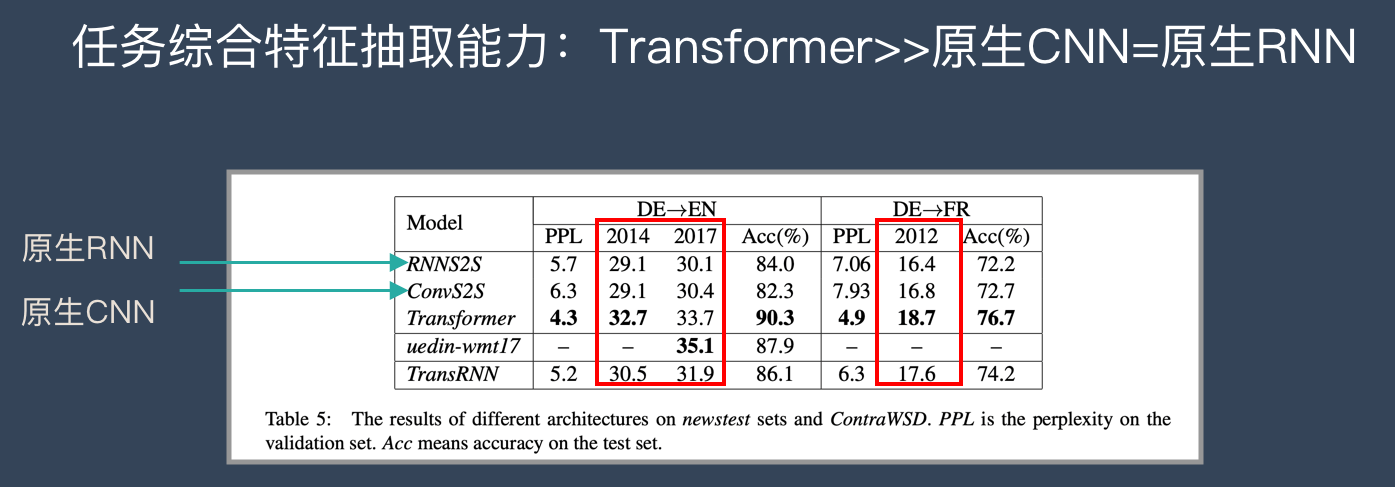
Transformer综合能力要明显强于RNN和CNN(技术发展到现在阶段,BLEU绝对值提升1个点是很难的事情),而RNN和CNN看上去表现基本相当,貌似CNN表现略好一些。

Transformer Base最快,CNN次之,再次Transformer Big,最慢的是RNN。RNN比前两者慢了3倍到几十倍之间。
Reference
1、开课吧—人工智能对话系统week 1课件

