JDK安装与配置 1、将JDK包解压至/usr/local目录下
1 sudo tar -zxvf jdk-8u271-linux-x64.tar.gz -C /usr/local/
2、配置环境变量,在/etc/profile或者用户的.bash_profile文件,在文件末尾处添加路径变量如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # export JAVA_HOME=/usr/local/jdk1.8.0_271 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin # --------------------------------------------------------------------- export JAVA_HOME=/usr/local/jdk1.8.0_271 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=$PATH:${JAVA_PATH}
你要将/usr/local/jdk1.8.0_271改为你的jdk安装目录;
linux下用冒号“:”来分隔路径;
${PATH}、${CLASSPATH}、${JAVA_HOME}是用来引用原来的环境变量的值,在设置环境变量时特别要注意不能把原来的值给覆盖掉了,这是一种常见的错误;
CLASSPATH中当前目录“.”不能丢,把当前目录丢掉也是常见的错误;
export是把这三个变量导出为全局变量;
大小写必须严格区分。
3、让修改的环境变量生效
设置SSH无密码登录 Hadoop是由很多台服务器所组成的,当启动Hadoop系统时,NameNode必须与DataNode连接并管理这些节点(DataNode)。此时系统会要求我们输入密码,为了让系统顺利运行而不需要手动输入密码,需要将SSH设置成为无密码登录。(无密码登录是以事先交换的SSH Key秘钥来进行身份登录)。Hadoop使用SSH(Secure Shell)连接,目前是最可靠、专为远程登录其他服务器提供的安全性协议。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 # 1、检查ssh和rsync是否安装 # ssh协议,rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件 rpm -qa | grep openssh rpm -qa | grep rsync # 2、若显示没有,则安装SSH和rsync dnf install ssh dnf install rsync # ------------------------------------------------ # 3、配置Master节点免密登录本机、所有的Slave # ------------------------------------------------ # (3.1)、产生SSH Key秘钥进行后续身份验证(可简写为ssh-keygen -t rsa -P '' ), # 生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/root/.ssh" 目录下。 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa # 默认在 ~/.ssh目录生成两个文件: # id_rsa :私钥 # id_rsa.pub :公钥 # 将产生的Key放置到许可证文件中 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # (3.2)、对于CentOS7.2及早期版本,(CentOS7.3及以后的版本跳过此步骤); # 修改ssh配置文件"/etc/ssh/sshd_config" 的下列内容,将以下内容的注释去掉: RSAAuthentication yes # 启用 RSA 认证 PubkeyAuthentication yes # 启用公钥私钥配对认证方式 AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同) # 重启ssh服务,才能使刚才设置有效。 service sshd restart # (3.3)、对于CentOS7.3以后的版本,在服务器上更改权限; # (很重要,如果不这么设置,就是不让你免密登录) chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys # (3.4)、验证无密码登录本机是否成功。 ssh localhost # (3.5)、导入要免密码登录的Slave服务器 # 首先将公钥复制到服务器 scp ~/.ssh/id_rsa.pub xxx@host:/home/id_rsa.pub # 然后,将公钥导入到认证文件(这一步的操作在服务器上进行) cat /home/id_rsa.pub >> ~/.ssh/authorized_keys # 最后在本地登录服务器 ssh -v hostname@hostip
Hadoop集群环境搭建 Hadoop安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 建议读者专门建立一个存放应用程序安装包文件夹,本文使用的是/opt,进入/opt目录下 cd /opt # 下载Hadoop: http://hadoop.apache.org/ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.5/hadoop-2.10.1.tar.gz # 解压缩 tar -zxvf hadoop-2.10.1.tar.gz # 移动hadoop到/usr/local /hadoop mv hadoop-2.10.1/* /usr/local/hadoop # 查看hadoop安装目录/usr/local /hadoop-2.10.1hadoop ll /usr/local/hadoop
配置Hadoop环境变量 在/etc/profile或者~/.bashrc添加文件内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 设置JDK安装路径 export JAVA_HOME=/usr/local/jdk1.8.0_271 # 设置HADOOP_HOME为Hadoop的安装路径/usr/local /hadoop export HADOOP_HOME=/usr/local/hadoop-2.10.1 # 设置PATH,这样在其他目录时仍然可以运行Hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin # 设置Hadoop其他环境变量 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME # 链接库的相关设置 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY
让~/.bashrc生效
修改Hadoop配置设置文件 主要包括:hadoop-env.sh、core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml
(1)设置hadoop-env.sh文件
1 vim /usr/local/hadoop-2.10.1/etc/hadoop/hadoop-env.sh
修改JAVA_HOME
1 2 3 4 5 6 7 8 export JAVA_HOME=/usr/local/jdk1.8.0_271 # 其中有博客文章配置的变量为:(https://www.cnblogs.com/nswdxpg/p/8526920.html) # export JAVA_HOME=/usr/local /jdk1.8.0_271# export HADOOP_HOME=/usr/local /hadoop-2.10.1# export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME /lib/native# export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME /lib" # export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
(2)设置core-site.xml
1 vim /usr/local/hadoop-2.10.1/etc/hadoop/core-site.xml
设置HDFS的默认名称:
1 2 3 4 5 6 <configuration > <property > <name > fs.default.name</name > <value > hdfs://localhost:9000</value > </property > </configuration >
这里需要注意的是:使用 fs.default.name 还是使用 fs.defaultFS ,要首先判断是否开启了 NN 的HA (namenode 的 highavaliable),如果开启了nn ha,那么就用fs.defaultFS,在单一namenode的情况下,就用 fs.default.name , 如果在单一namenode节点的情况使用 fs.defaultFS ,系统将报错误如下:
ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
(3)设置yarn-site.xml
1 vim /usr/local/hadoop-2.10.1/etc/hadoop/yarn-site.xml
在之间输入:
1 2 3 4 5 6 7 8 9 10 <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.aux-services.mapreduce.shuffle.class</name > <value > org.apache.hadoop.mapred.ShuffleHandler</value > </property > </configuration >
(4)设置mapred-site.xml
1 2 3 cp /usr/local/hadoop-2.10.1/etc/hadoop/mapred-site.xml.template /usr/local/hadoop-2.10.1/etc/hadoop/mapred-site.xml nano /usr/local/hadoop-2.10.1/etc/hadoop/mapred-site.xml
在之间输入:
1 2 3 4 5 6 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > </configuration >
(5)hdfs-site.xml
1 vim /usr/local/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
在之间输入,默认的blocks副本备份数量是每一个文件在其他node的备份数量,默认值为3。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <configuration > <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.namenode.name.dir</name > <value > file:/usr/local/hadoop-2.10.1/hadoop_data/hdfs/namenode</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > file:/usr/local/hadoop-2.10.1/hadoop_data/hdfs/datanode</value > </property > </configuration >
创建并格式化HDFS目录 1 2 3 4 5 6 7 8 9 10 11 # 创建namenode数据存储目录 mkdir -p /usr/local/hadoop-2.10.1/hadoop_data/hdfs/namenode # 创建datanode数据存储目录 mkdir -p /usr/local/hadoop-2.10.1/hadoop_data/hdfs/datanode # 将Hadoop的所有者更改为root chown root:root -R /usr/local/hadoop-2.10.1 # 格式化HDFS,如果HDFS已有数据,格式化操作会删除所有的数据 hadoop namenode -format
启动Hadoop 分别启动HDFS和YARN,使用start-dfs.sh(启动HDFS)和使用start-yarn.sh(启动YARN)
1 2 3 4 5 6 7 8 9 10 11 # 启动HDFS # start-dfs.sh # 启动YARN # start-yarn.sh # 或者同时启动HDFS和YARN start-all.sh # 使用jps查看已经启动的进程,查看NameNode和DataNode进程是否启动 jps
HDFS功能:NameNode、SecondaryNameNode和DataNode
Hadoop ResourceManager Web界面查看Hadoop运行状态:node、application和status. http://master_ip:8088
在VMware虚拟的CentOS8中,宿主机并不能访问虚拟机的IP端口,但是能ping得通,centos7 防火墙由firewalld管理,service firewalld stop关闭防火墙即可。
参考:
1、https://blog.csdn.net/weixin_40814247/article/details/95042886
2、win7无法访问虚拟机中的hadoop2.x的web管理界面
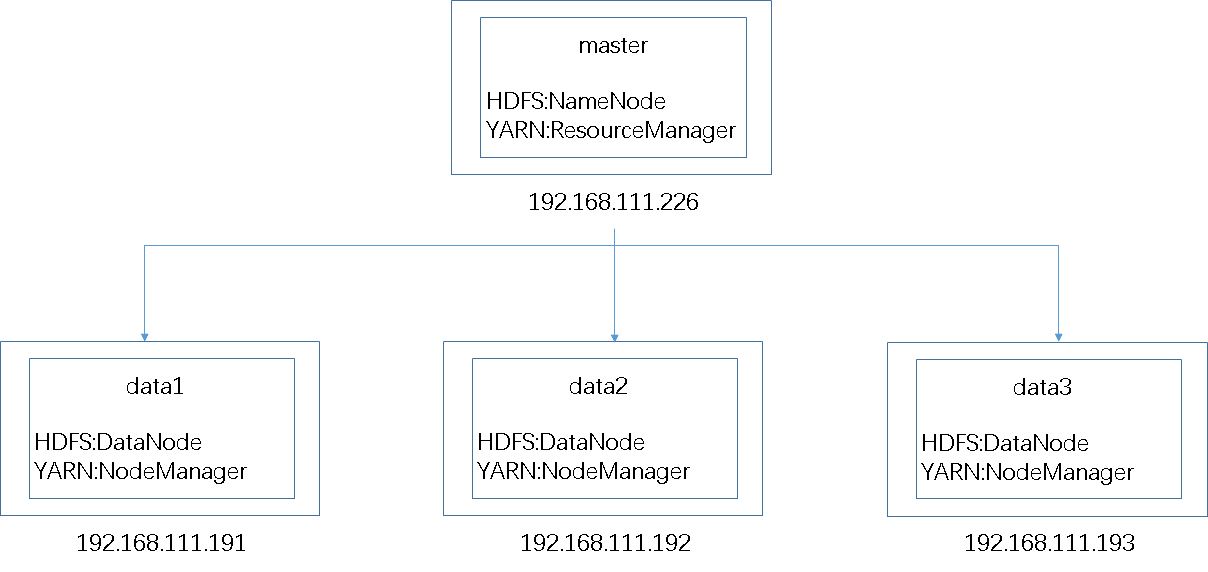
Hadoop集群的搭建 前面我们只用了一台机器,实际生产中,不可能这样操作,我们的通常做法是:http://192.168.111.227:8088/cluster一样,就是辅助节点。】
Reference:
1、Ubuntu下SSH无密码验证配置
2、CentOS7.4配置SSH登录密码与密钥身份验证踩坑
3、本地CentOS8 配置ssh免密登录服务器
2、Spark学习笔记—Linux安装Spark集群详解
1、推荐系统中的A/B测试,谁能详细说下思路?