Spark任务提交方式
Standalone模式两种提交任务方式
Standalone-client提交方式
提交命令:
...代表spark安装目录
./spark-submit —master spark://hadoop101:7077 —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
./spark-submit —master spark://hadoop101:7077 —depoly-mode client —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
执行流程:
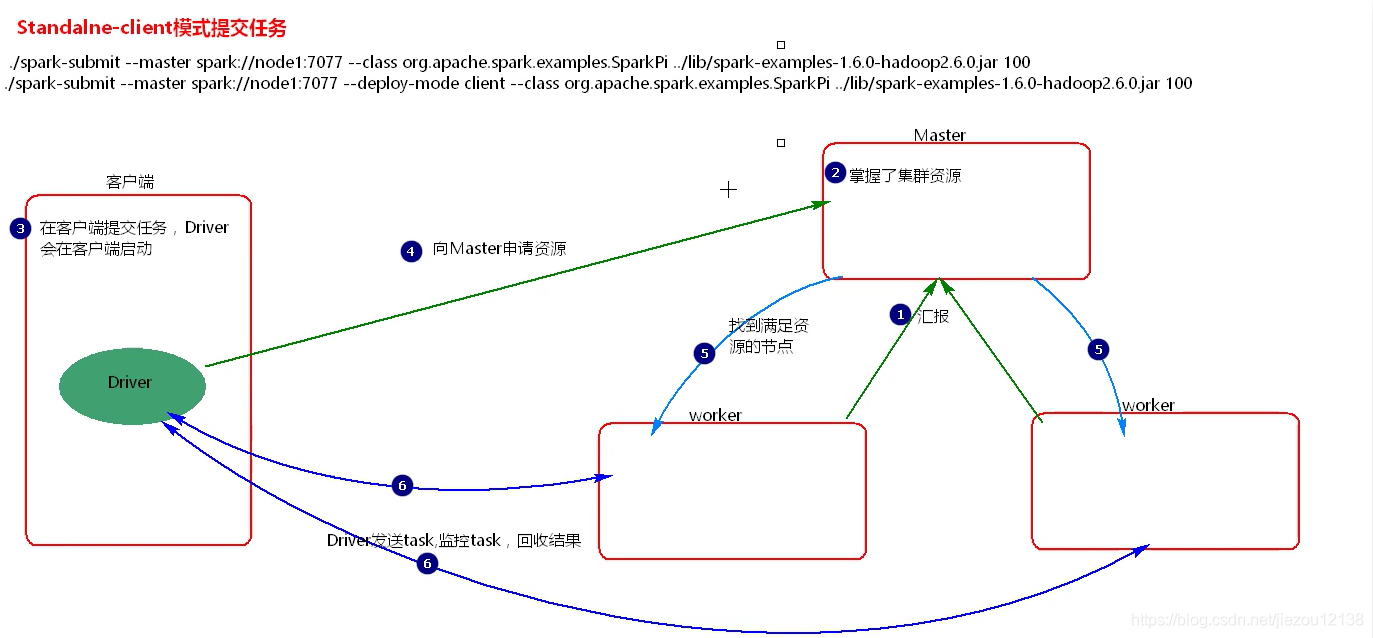
1、在客户端提交Spark应用程序,会在客户端启动Driver。
2、客户端向Master申请资源,Master找到资源返回。
3、Driver向worker节点发送task,监控task执行,回收结果。
执行原理图解:
总结:
1、client方式提交任务,在客户端提交多个application,客户端会为每个application都启动一个Driver, Driver与集群Worker节点有大量通信,这样会造成客户端网卡流量激增。
2、在客户端可以看到task执行情况和计算结果。
3、client方式提交任务适用于程序测试,不适用于真实生产环境。
Standalone-cluster提交任务方式
提交命令:
./spark-submit —master spark://hadoop101:7077 —depoly-mode cluster —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
执行流程:
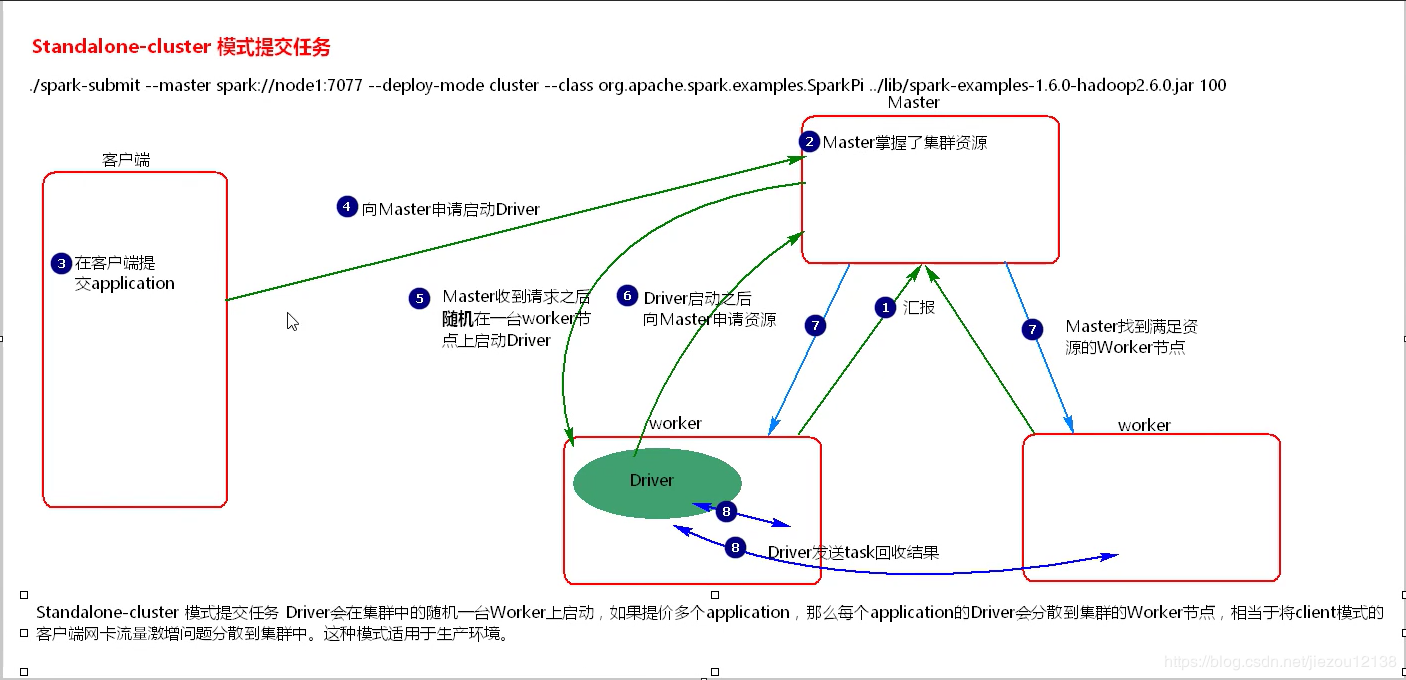
1、客户端提交application,客户端首先向Master申请启动Driver。
2、Master收到请求之后,随机在一台Worker节点上启动Driver。
3、Driver启动之后,向Master申请资源,Master返回资源。
4、Driver发送task,监控task执行,回收结果。
执行原理图解:
总结:
cluster方式提交任务,Driver在集群中的随机一台Worker节点上启动,分散了client方式的网卡流量激增问题。 cluster方式适用于真实生产环境,在客户端看不到task执行情况和执行结果,要去WEBUI中去查看。
Driver的功能
在standalone模式中Driver的功能
1、发送task
2、监控task执行,回收结果
3、申请资源
yarn模式两种提交任务方式
yarn-client提交任务方式
提交命令:
./spark-submit —master yarn —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
./spark-submit —master yarn-client —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
./spark-submit —master yarn —depoly-mode client —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
执行流程:
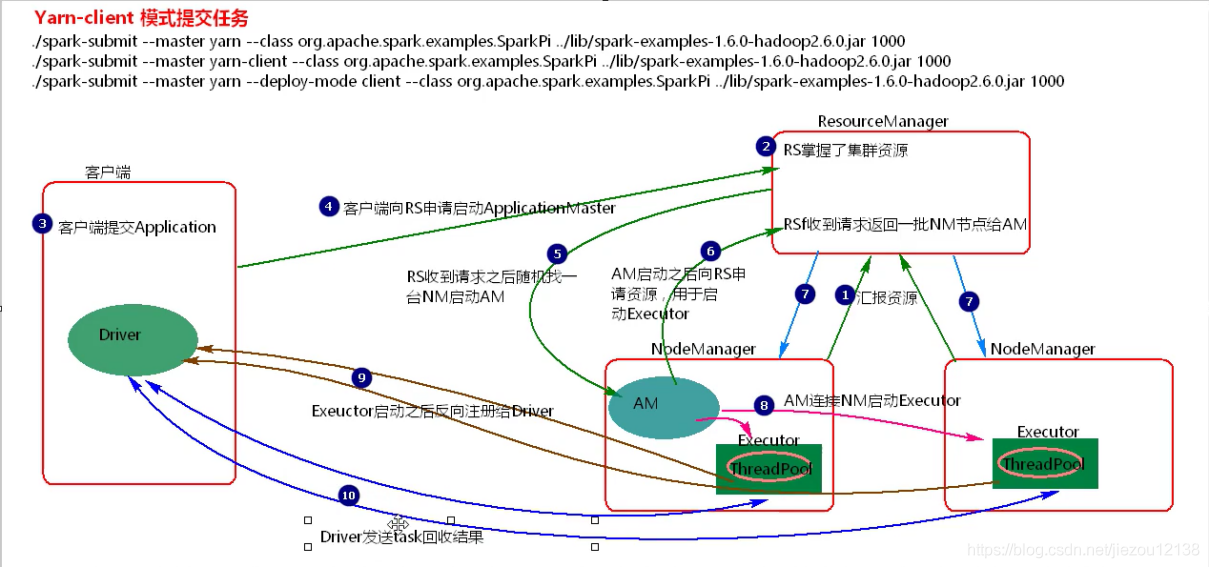
- 客户端提交application,Driver会在客户端启动
- 客户端向ResourceManager申请启动ApplicationMaster
- ResourceManager收到请求之后,随机在一台NodeManager中启动ApplicationMaster
- ApplicationMaster启动之后,向ResourceManager申请资源,用于启动Executor
- ResourceManager收到请求之后,找到资源返回给ApplicationMaster一批NodeManager节点
- ApplicationMaster连接NodeManager启动Executor
- Executor启动之后会反向注册给Driver
- Driver发送task到Executor执行,监控task的执行并回收结果
执行原理图解:
总结:
Yarn-client模式提交任务,Driver在客户端启动,当提交多分application,每个application的Driver都会在客户端启动,也会有网卡流量激增问题,这种模式适用于程序测试,不适用与生产环境,在客户端可以看到任务的执行和结果。
Yarn-cluster提交任务方式
提交命令
./spark-submit —master yarn —depoly-mode cluster —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
./spark-submit —master yarn-cluster —class org.apache.saprk.examples.SparkPi …/examlpes/jars/spark-examples_2.11-2.2.0.jar 100
执行原理图解
执行流程
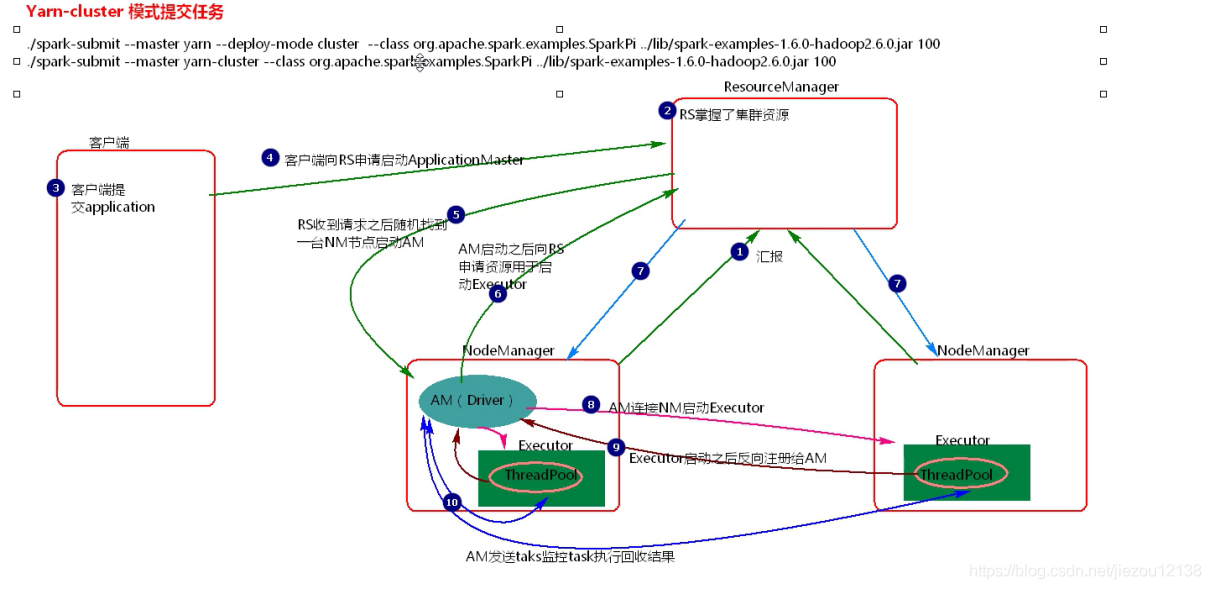
1、客户端提交Application,首先客户端向ResourceManager申请启动ApplicationMaster(AM)
2、ResourceManager收到请求之后,随机在一台NodeManager中启动ApplicationMaster,这里ApplicationMaster就相当于是Driver
3、ApplicationMaster启动之后,向ResourceManager申请资源,用于启动Executor
4、ResourceManager收到请求之后,找到资源返回给ApplicationMaster
5、ApplicationMaster连接NodeManager启动Executor
6、Executor启动之后会反向注册给ApplicationMaster(Driver)
7、ApplicationMaster(Driver)发送task到Executor执行
总结
Yarn-cluster模式提交任务,使用于生产环境,AM(Driver)\随机**在一台NM节点上启动,当提交多个application时,每个application的Driver会分散到集群中的NM中启动,相当于将Yarn-client模式的客户端网卡流量激增问题分散到集群中。在客户端看不到task执行和结果,要去WEBUI中查看。
Application功能
在Yarn模式下Application(Driver)的功能
- 申请资源
- 启动executor
- 任务调度(包含上面Driver的功能)
术语解释
- Master(Standalone):资源管理的主节点(进程)
- Cluster Manager:在集群上获取资源的外部服务(例如standalone、Mesos、Yarn)
- Worker Node(standalone):资源管理的从节点(进程),或者说管理本机资源的进程
- Application:基于Spark的用户程序,包含了Driver程序和运行在集群上的executor程序
- Driver Program:用来连接工作进程(Worker)的程序
- Executor:是在一个worker进程所管理的节点上为某个application启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应用都有各自独立的executors。
- Task:被送到某个executor上的工作单元
- Job:包含恨到任务(Task)的并行计算,可以看作和action对应
- Stage:一个job会被拆分很多组任务,每组任务被称为Stage(就像MapReduce分为map task和reduce task一样)
Spark任务调度和资源调度
spark资源调度和任务调度流程
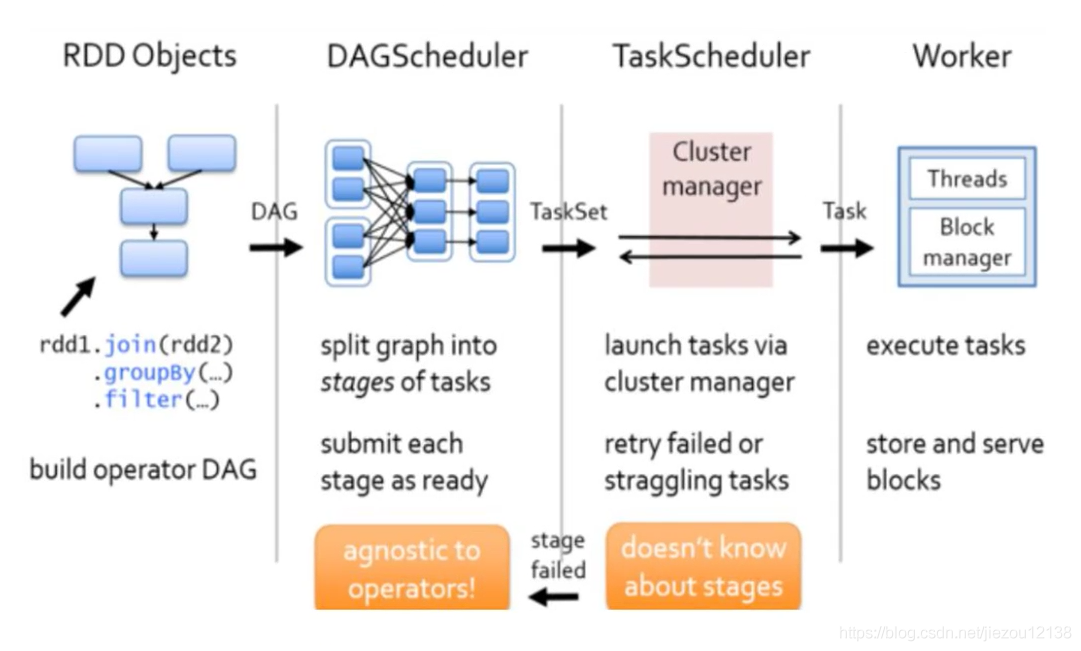
启动集群后,Worker节点会向Master节点汇报资源情况,Master掌握了集群资源情况。
当Spark提交一个Application后,根据RDD之间的依赖关系将Application形成一个DAG有向无环图。
任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler,DAGScheduler是任务调度的高层调度器,是一个对象。DAGScheduler的主要作用就是将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage,然后将这些Stage以TaskSet的形式提交给TaskScheduler(TaskScheduler是任务调度的低层调度器,这里TaskSet其实就是一个集合,里面封装的就是一个个的task任务,也就是stage中的并行度task任务),TaskSchedule会遍历TaskSet集合,拿到每个task后会将task发送到计算节点Executor中去执行(其实就是发送到Executor中的线程池ThreadPool去执行)。
task在Executor线程池中的运行情况会向TaskScheduler反馈,当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就失败了。stage失败了则由DAGScheduler来负责重试,重新发送TaskSet到TaskSchdeuler,Stage默认重试4次。如果重试4次以后依然失败,那么这个job就失败了。job失败了,Application就失败了。(*\*Job=多个stage,Stage=多个同种task****)
TaskScheduler不仅能重试失败的task,还会重试straggling(落后,缓慢)task(也就是执行速度比其他task慢太多的task)。如果有运行缓慢的task那么TaskScheduler会启动一个新的task来与这个运行缓慢的task执行相同的处理逻辑。两个task哪个先执行完,就以哪个task的执行结果为准。这就是Spark的推测执行机制。在Spark中推测执行默认是关闭的。推测执行可以通过spark.speculation属性来配置。
注意:
对于ETL(数据清洗)类型要入数据库的业务要关闭推测执行机制,这样就不会有重复的数据入库。
如果遇到数据倾斜的情况,开启推测执行则有可能导致一直会有task重新启动处理相同的逻辑,任务可能一直处于处理不完的状态。
推测执行机制默认是关闭的。
图解Spark资源调度和任务调度的流程
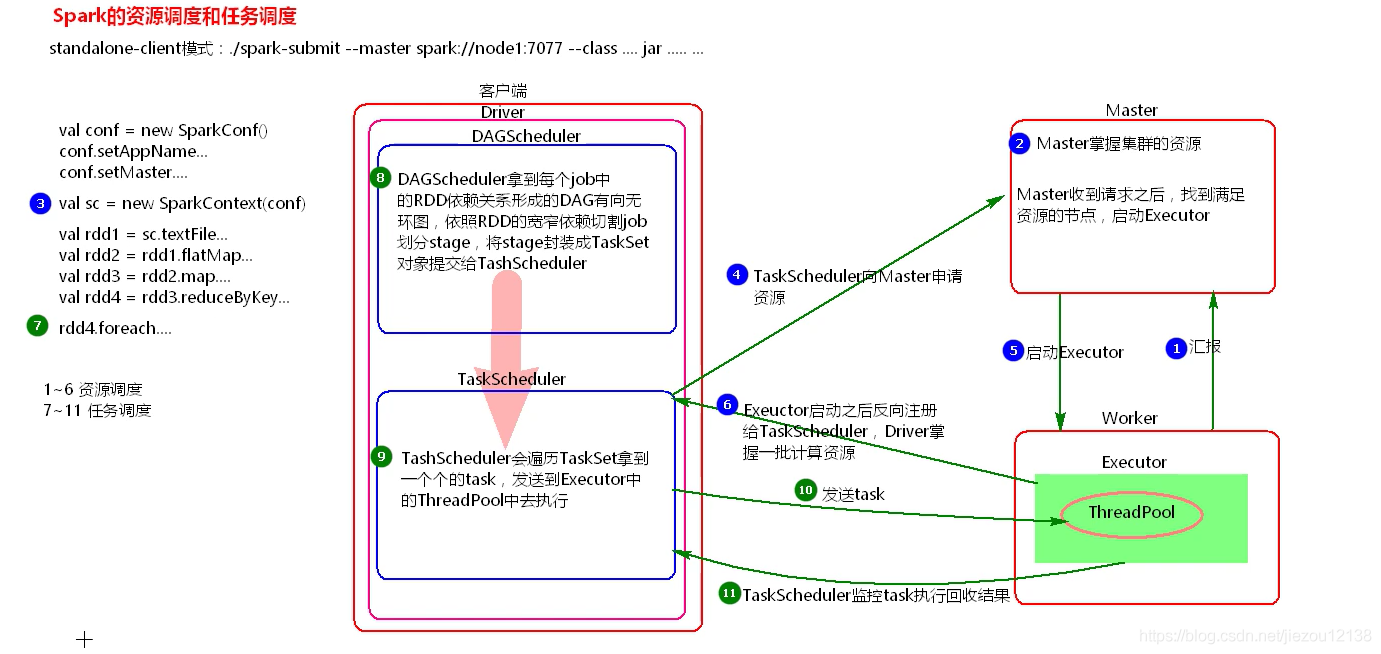
粗粒度资源申请和细粒度资源申请
粗粒度资源申请(Spark)
获取到所有资源后才开始任务,执行完所有任务后释放资源;任务执行速度快,但是资源就无法充分利用。
在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后, 才会释放这部分资源。
优点:在Application执行之前,所有的资源都申请完毕,每一个task直接使用资源就可以了,不需要task在执行前自己去申请资源,task启动就快了,task执行快了,stage执行就快了,job就快了,application执行就快了。
缺点:直到最后一个task执行完成才会释放资源,集群的资源无法充分利用。
细粒度资源申请(MapReduce)
执行时每一个task去提前获取资源,执行完就释放资源;资源的利用率高,但是这样执行的效率就慢
Application执行之前不需要先去申请资源,而是直接执行,让job中的每一个task在执行前自己去申请资源,task执行完成就释放资源。
优点:集群的资源可以充分利用。
缺点:task自己去申请资源,task启动变慢,Application的运行就相应的变慢了。
Reference

