hive 的一些配置
1
2
3
4
5
6
7
8
| //显示所在数据库名
set hive.cli.print.current.db=true;
//显示字段名
set hive.cli.print.header=true;
//不显示表名
set hive.resultset.use.unique.column.names=false;
|
或者在hive/conf/hive-site.xml文件中添加配置项:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.resultset.use.unique.column.names</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
|
hive执行聚合任务卡在Kill Command不动假死
问题描述:
在hive中执行了“select count(*) from ll_voucher_issue”后,一直无反应,具体为:
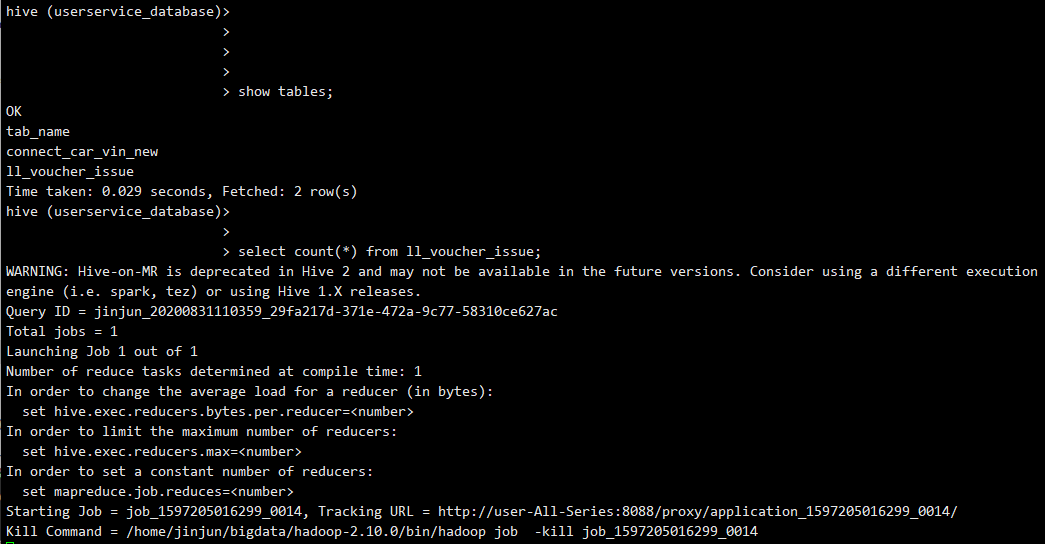
但若是执行其他非MR运算如select * from table limit 10,则不会卡住。
PS:
1、hadoop伪分布式搭建好后,使用hadoop dfsadmin -report可以查看,是否所有的节点都已经成功启动。
2、使用jps查看进程,应该会有datanode, nodemanger, namenode, secondrynamenode, resourcemanger这些进程,如果缺少那一个的话,那证明hadoop环境没有成功启动。
问题原因:
猜测是Hive没有连接上mapreduce,通过检查hive-env.sh发现。
解决方案:
1、配置hive/conf/hive-env.sh(未尝试,先记录下来)
1
2
| HADOOP_HOME=/apps/hadoop
export HIVE_CONF_DIR=/apps/hive/conf
|
2、修改hadoop/etc/hadoop/mapred-site.xml(解决)
1
2
3
4
5
6
7
| <configuration>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://master:8001</value>
<final>true</final>
</property>
</configuration>
|
原mapred_site.xml文件配置为:
1
2
3
4
5
6
| <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
Reference:
1、hive执行任务MR时卡死/假死
2、hive执行job时候假死,kill comman卡住解决办法
3、hive建表语句详解
4、BigData-Notes

